
Feb 16th 2019
We took the UAV out to the soccer field and flew it at a height of 12m. We placed litter (solo cups and coffee cups) on the grass and took pictures. Below is one of the images we captured.

Shortly after, we implemented a naive thresholding algorithm in an attempt to isolate the background from everything else in the image. Below is the output of this thresholding step (on a different image).

March 9th, 2019
By this time, we had collected images over five different days and in different environmental conditions. We had images in both natural grass and Astroturf, and in sunny, partly cloudy, cloudy, overcast and fading-light conditions. In total, we had around 200 images in our dataset, which provided a strong foundation on which to build our vision pipeline.
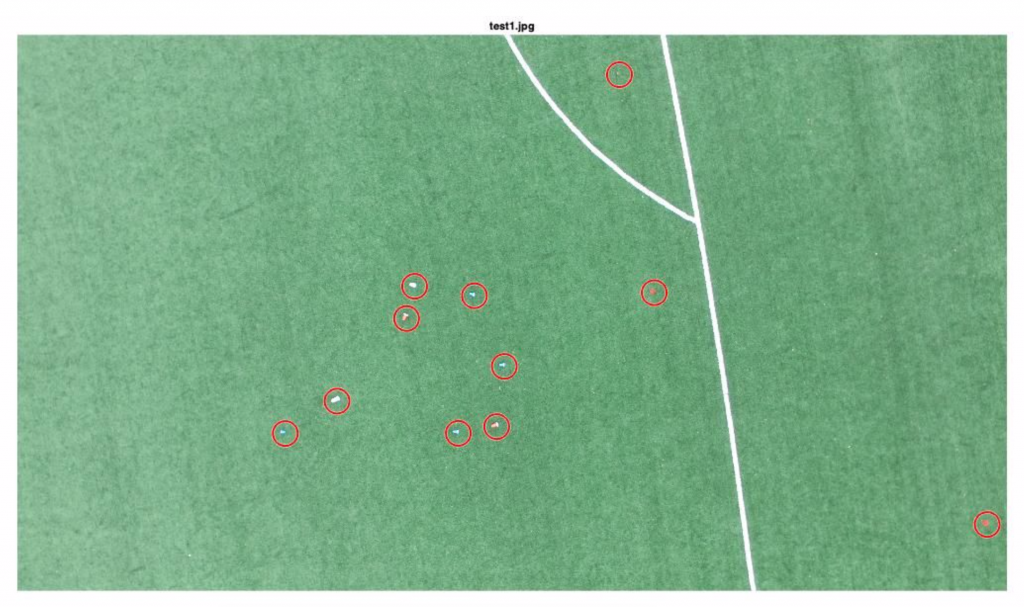
Since our initial naive thresholding algorithm was not robust to changing lighting conditions and noise, we found an alternative, but similar algorithm that was developed for autonomous lawn mowers. Our new algorithm — called dynamic color thresholding — computed suitable thresholds for the grassy background based on global image data. With those thresholds, we were able to “remove” majority of the background (grass) from the image, leaving only the litter, field markings and random noise in the image. In order to address the field markings, we simply ignored contiguous blobs that were larger than some size and found that worked very well. For the random noise, we did the opposite by ignoring blobs that were too small to be litter objects. Since we computed our thresholds dynamically for each image, our new pipeline is robust to changing lighting conditions. However, there is still the issue of false positives that cannot be filtered out using the method outlined above. Namely, large objects like leaves and napkins are also detected and cannot be filtered out based on size alone. The images below show the output of our pipeline. Each of the red circles covers an area that the pipeline thinks is litter.

March 27th
Based on our learnings from the dynamic color thresholding prototype, it is clear that we need to build some sort of classifier to remove as many false positives as possible. Unfortunately, there is no existing dataset that is available for us to use. Therefore, we will have to build this ourselves. We have written some code that generates potential patches of interest in the image where we believe there may either be litter present or some other interesting item. We have also collected examples of just grass to represent our ‘negative’ samples. In total, we have collected 1600 samples patches that we will use to train and test our classifier. Based on preliminary tests, we believe that gradient-based features will be effective in discriminating between litter and non-litter patches. Therefore, we plan to use a Support Vector Machine (SVM) with Histogram of Oriented Gradients (HOG) features as our classifier. The image below is an example of positive and negative samples from our dataset.

SVD Implementation Description
Our initial vision system used basic thresholding to determine the litter locations in the scene. However, this did not work well and resulted in numerous false positives being detected largely due to the high sensitivity of naive thresholding to changing environmental conditions (lighting, shadows etc.). The next iterations used a method borrowed from autonomous lawn mowers and building on the first version – dynamic color thresholding. The underlying assumption of this algorithm is that the background of the image is homogeneous (like grass or sand) and we found this approach to work significantly better. We were able to consistently identify all the litter in the scenes, but we were still seeing a non-negligible number of false positives (leaves, field markings, cones etc.). Therefore, our next step was to add a classifier to remove the false positives. We wrote a script to automatically generate images patches from the images we had already collected which we could use as a training and testing set. From the almost over images we had captured, we hand-labelled 1600 samples into positive and negative sets. Since we still needed a lot more training data, we augmented the dataset by applying various transformations to the existing images, growing our dataset from 1600 samples to over 200000. We chose to use a Support Vector Machine (SVM) as our classifier as prior literature on the subject has proven it to be suitable for object detection. We trained a SVM using a linear kernel on our training set and achieved a testing accuracy of 95%.
Recognization Result during SVD:

Litter identification on sand terrain:


Fall 2019 Updates (including FVD)
In the Fall semester, we did not make any significant changes to our litter detection pipeline. The one modification we had to make was with regard to the input image size. When we began transferring images from the UAV to the server via ROS, we discovered that their resolution was being reduced to 1280 x 720px as compared to the 4000 x 2250px we were using earlier. Therefore, I had to retrain my SVM classifier and update our pipeline to handle these lower resolution images. The performance of our pipeline on sand and grass environments are shown below and match what we produced for our FVD.

