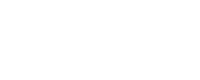
Motion Planning
The motion planning is currently executed in two parts. The first part is when the single arm controller takes in the grasp points from the object pose estimation and execute the trajectory for each arm separately. This means that the arms don’t need to be working together at this point, hence they might reach the grasp points at different times. The second part is when the arms have grasped the object and now needs to work together essentially as one system to maneuver it, following the manipulation policy.
Environment Setup
- Successfully configured a dual-arm system in MoveIt2 using the Kinova Kortex platform
- Extended the official ROS2 single-arm package to support two arms in the same environment
- Added environmental objects (Vention table and sample bin) for collision avoidance
- Established collision awareness between all components in the workspace
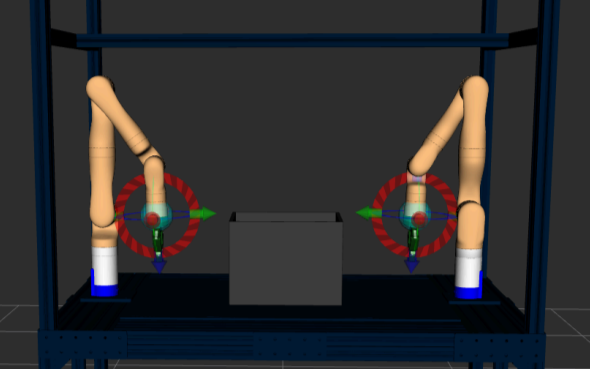
Motion Planning Capabilities
- Implemented RRT* planning algorithm for trajectory generation
- Configured ROS2 controllers according to Kinova software requirements
- Achieved simultaneous planning and execution for both arms
- Successfully tested planning and execution in fake hardware mode, Gazebo simulator, and real hardware
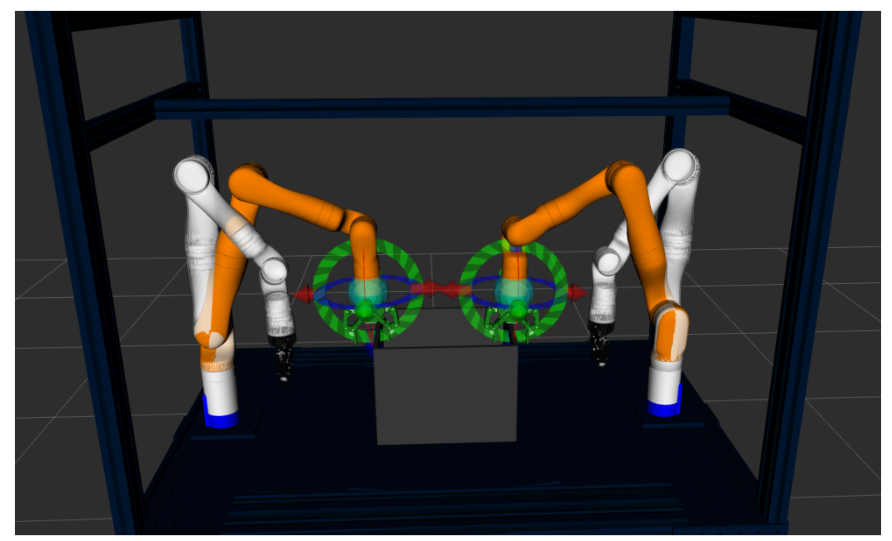

Finite State Machine for Manipulation Policy
- Developed a dedicated ROS2 package that automates the planning and execution process
- Replaced manual goal-setting in Rviz with programmatic goal specification
- Established a pipeline for feeding in the position of the bin to spawn in Rviz for motion planning
- Order of FSM:
- Subscribe to aruco pose topic that gives x and y pose of bin
- Spawn it in Rviz
- plan and move to grasp points calculated from centroid of bin
- close grippers
- Attach the arms to the bin as one kinematic chain and lift the bin
- Rotate the bin backward to show the bottom face
- Rotate the bun forward to show the top face
- Place back to its original bin position
- Go to home
Improving Robustness for Manipulation Policy
- Switched from joint space planning to Cartesian-based planning where we have a linear trajectory of the end effector from current to target pose
- Integrated with 3D pose estimation pipeline so that the arms are able to grasp the object in a range x and y positions and yaw angles
- x, y positions: (0,0) +/- 10 cm in any direction
- yaw angle: 35-55 degrees
Application to Coupler Object and Stretch Goal object
- Demonstrate flexibility of manipulation policy to many objects
- FSM for objects:
- Subscribe to pose estimation that gives x position, y position, yaw angle of the object
- Spawn in Rviz
- Go to object and approach first two grasp points
- Grasp objects
- Lift object, do 360 rotation
- Place down, release gripper one at a time
- Grasp second two grasp points (perpendicular to first two)
- Lift and do 360 rotation
- Place down and go to home pose

3D Reconstruction
Data Collection
- Capture RGBD frames during object rotations
- Capture transformations by solving FK for both end-effectors

Preprocessing
- Align camera frames with the corresponding transform using timestamps
- Run SAM 2 segmentation to get the object mask

- Filter the points using the mask and then unproject them from the image to the camera frame
- Transform all the points from the camera frame to the world frame using the transformation matrix obtained from the ARUCO-based camera calibration
- Downsample the points and filter by depth threshold to get rid of excess noise
- Align the transformed points using the transformation obtained from the arm first
- Refine the alignment using general ICP, which uses both point-to-point and point-to-plane ICP with a weighted average to compute the alignment.
- Stack all the aligned point clouds and save as a ply file

Object Pose Estimation
1. Handle Redesign & Visual Encoding
To enable robust multi-handle detection, the object was redesigned with four distinctly colored handles: handle_o, handle_r, handle_c, and handles.
This visual encoding minimizes false detections, eliminates class ambiguity, and provides strong geometric cues for orientation estimation.
2. Multi-Handle Detection Using YOLOv11
A custom YOLOv11-based detection model was trained on a dataset covering varied lighting, object orientations, and workspace conditions.
The model identifies all four handle classes with high confidence, ensuring stable and high-frequency detections suitable for real-time robotic manipulation.
3. World-Space Projection & Pose Computation
Detected 2D handle locations are mapped into the world frame using calibrated camera parameters.
By leveraging the relative spatial configuration of the four handles, the system computes:
- Accurate 3D center position
- Stable and redundant yaw estimation
- Low-jitter pose output optimized for control loops
This multi-handle geometry eliminates orientation flips and improves robustness under motion.

4. Real-Time Pose Publishing for Manipulation
The final pose, consisting of (x, y, z, yaw), is published as a ROS PoseStamped message for downstream consumption.
The perception pipeline operates at real-time rates, providing continuous, high-precision pose updates that directly feed into manipulation, alignment, and grasping behaviors.

Object Transforms
For a successful integration between the 3D reconstruction pipeline and the manipulation pipeline, we need to localise the object’s pose in a common coordinate system to stitch the collected point clouds. We initially tried to get the pose information using deep learning methods like FoundationPose and other State-Of-The-Art models for 6D pose tracking. However, due to lack of features, these models could not provide accurate representation of the object in 3D space.
We then decided to use the information from the manipulators to backtrack the pose of the object. By calculating the poses of the end-effectors of the robotic arms in the world frame, we were able to interpolate it to the center which is supposed to be the object pose as well. This approach gave us a better localisation of the object directly in the world frame without requiring further processing. This transforms are then fed to the reconstruction pipeline where the timestamps between the recorded pointclouds and the timestamps of the transforms are matched and used for the object pose.
