Oct 20. The gaze subsystem set-up
Two of the cameras faces towards the pupils, and the other faces towards the environment. From the image of the rest camera, we will locate the pupils, and analyze the direction. After calibration, the location of the gaze is mapped to the world-frame images. At the same time, the gaze tracking subsystem is also listening to the information from the environment perception system, which is publishing the objects detected in the working space and their position. According to the relative distance from the gaze and the center of the object, a confidence is obtained.
Communication of the gaze node and AprilTag node is finished. The environment reconstruction is finished in AprilTag Node.

Oct 27. Gaze based possibility
The model between gaze based and confidence should be following:
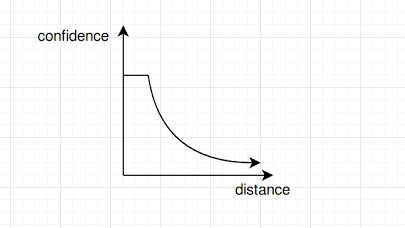
When the gaze is in one of the bounding box, the gaze based confidence for that
object should be very high. And as long as the gaze is in the bounding box, which means no matter which part of the object you are gazing at, the confidence should remain the same. If your gaze is not in the bounding box of any of the objects, then the gaze based confidence should be proportional to one over the distance.
Nov 10. Intent Prediction
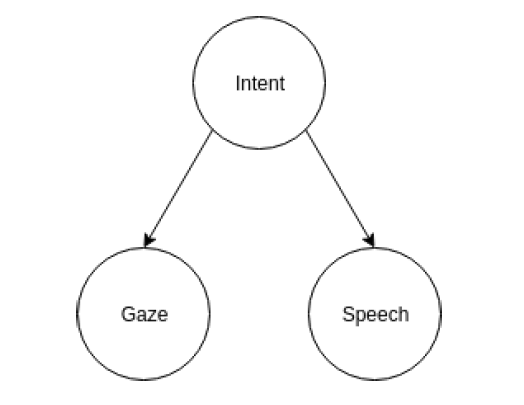
When the user wants one of the objects in the work space, he would gaze at the object,
and give a command containing the objects. Under such assumption, given the intent,
the gaze would not add more information for speech, so they are conditional independent.
The relationship is described in the following figure.
Nov 22. Update for the gaze possibility
The gaze possibility is accumulated over the time of speech, assuming that when the user is giving the command, the gaze would locate around the target most of the time.
February 22. We Go Deep
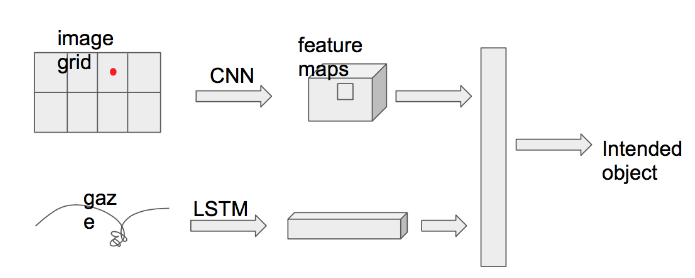
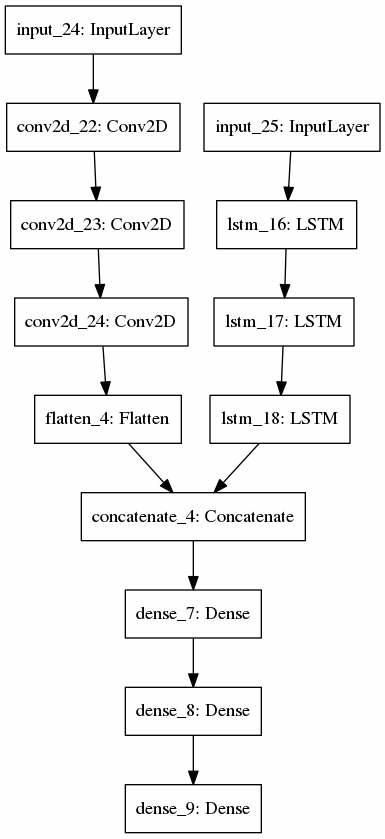
While the previous approach has been very successful and has fulfilled our requirements. The intent prediction requires the user to stare at the object constantly and causes significant strain to user’s eyes in a prolonged interaction. So we decided to use deep learning techniques to learn the user’s gaze pattern and use that pattern to predict the object that the user intends to pick up. We have decided to use a multi-modal approach where we combine the information from the environment-facing camera and the gaze location. Below are our two proposed neural networks.
March 23: Data Collection and Initial Results
To train our model, we collected and labeled our own data set. The data set consists of 260 interactions where the user requested for an item on the table and is handed that item by the experimenter. After collecting the data we annotated the time when the gaze is shown to be expressing the intent of the object to be picked up.
This image demonstrated the experimental setup. Here we have the user staring at the table with the operator standing across the table. The user will request for an item they want and the operator will hand it over. The red dot here represent the location that the user is gazing at.

This is the example of our data annotation process. We annotate the start and end time when the user’s gaze exhibits intend

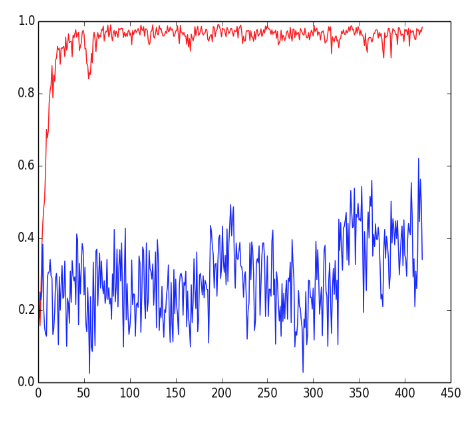
This graph is the initial training result of our neural network. The red line is the training error and the blue line is the validation error. While we obtained very high training error, the model overfitted the dataset and, consequently, had a relatively low validation error.
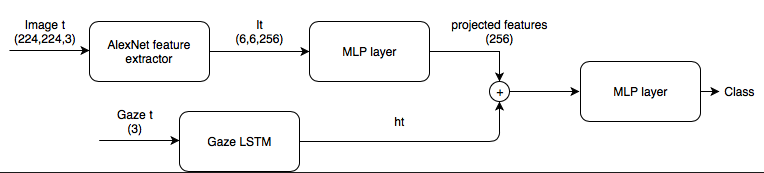
April.11th: LSTM-based Model for Intention Prediction
- LSTM Baseline Model: Use AlexNet as a feature extractor. Use LSTM to process the gaze sequence. Simply concatenate gaze and image features and feed to the MLP.
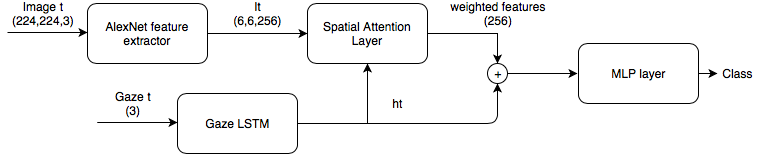
- Spatial Attention Model: Add spatial attention layer to assign different weights to each region based on the baseline model.
- Multiple Attention Model: Add temporal attention layer to assign different weights for each frame based on the spatial attention model.

April.17th: Back-up Model: Simple Classification Model
- Simple Classification Model: Use the position of gaze to crop the world image. Use AlexNet as a classifier.
