Functional Architecture
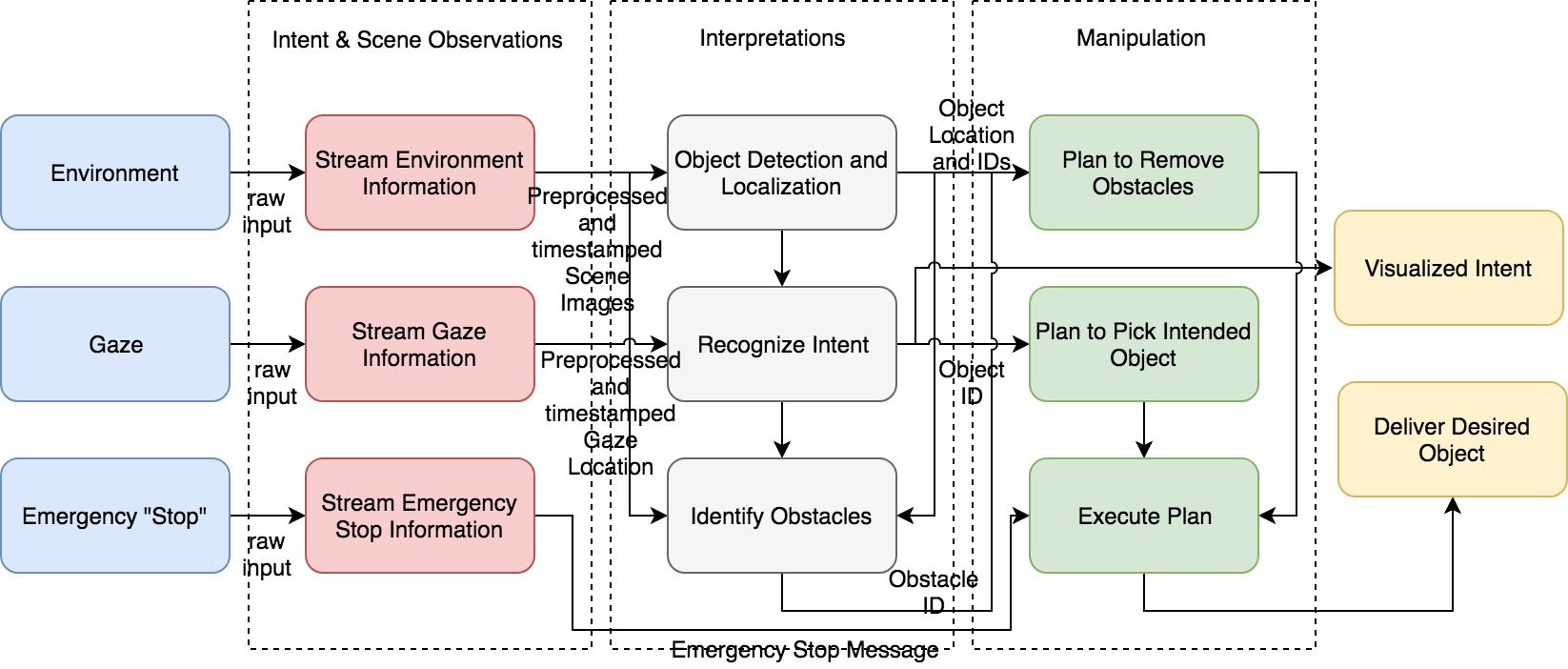
The intent bot system can be divided into three subsystems:
- Intent and Scene Observation
- Intent interpretation
- Manipulation
The Intent bot observes the user and the user’s environment, which is the table, for the objects. While observing the user it takes as an input the user’s gaze and speech. Also, it observes the locations of the various objects in the scene which will be used for the manipulation subsystem.
Based on the observations, the intent bot predicts the intent of the user. It essentially combines the speech(not used in the SVE) and the gaze, fuses it together and probabilistic ally determines whether the user wanted a certain object in the scene or not. This intent, once determined is passed to the manipulation subsystem as a target.
The manipulation subsystem plans the grasping to the target object. It loads the objects in the environment from the scene observation subsystem and then plans a trajectory for placing and picking by avoiding collision with the various objects. On top of everything, the manipulator instantly stops in case of an emergency system.
Cyber-physical Architecture
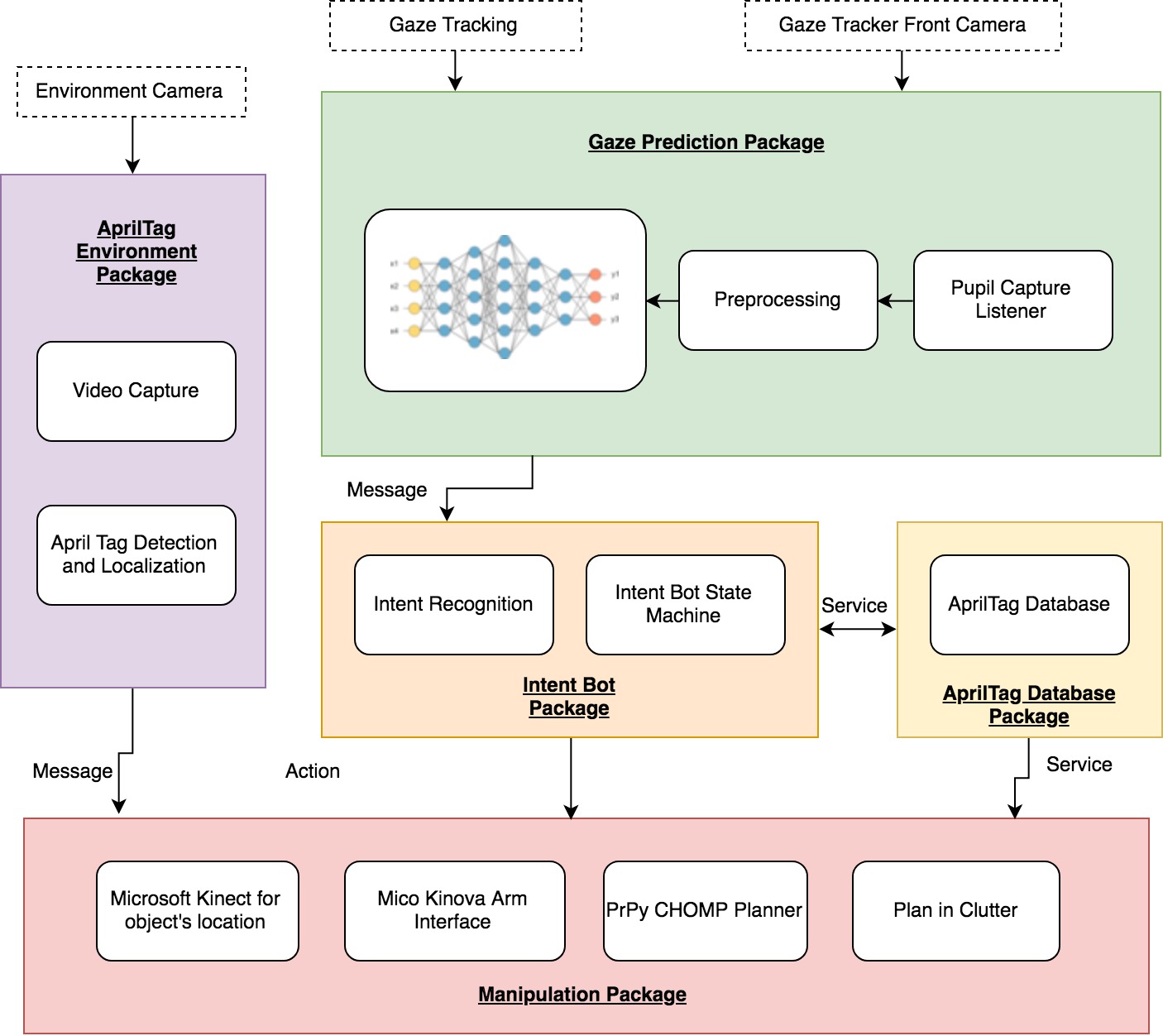
The current cyberphyscial architecture has been revised based on the ROS framework setting for the intent bot.
The various blocks in the architecture correspond to a ROS Node. Various messages flow in between the nodes and are used to perform essential tasks.
- Speech(not included in the SVE)
The Speech node uses Py-Audio to record audio signals. This is passed to the Google Speech API to identify the PosTAGS which are ultimately used to identify the objects that the user intends to pick. The Speech is an action server which triggers the manipulation server when the final intent has been recognized. - Gaze Tracking and Gaze Tracking Front CameraThis node performs the interface with the pupil lab glasses to get what the user is actually viewing . Two cameras are used in the glasses. One tracks the user’s pupils and the other sees the outside world. The outside world camera or the front camera detects the April tags on the objects. Based on this, the gaze node draws two bounding boxes on the object. One corresponds to the gaze and the other corresponds to the detected object dimensions. This an overlap between the boxes determines the probability that the user is gazing ata a particular object.
- Intent Bot PackageThis is the package which takes in the Speech input action and the input from the gaze tracking and front camera to calculate the intent probabilities. Based on the probabilities that are calculated out a sample space of the target ids on the table, the id is passed on to the manipulation node.
- Manipulation The manipulator is an action server and performs an action based on the target id which is requested. While it is doing the manipulation it gives the feedback to the nodes which are its clients in the form of numbers interpreted as various stages in the manipulation process.