Intent Bot System
The Intent Bot could recognize the intent of receiving speech command and the gaze from the user. It could calculate the probability of which object the user wants, then bring the object to the user. The whole system could be broken down into four subsystems including manipulation, speech, gaze and environment recognition. The integration of the whole system and all of the subsystems will be elaborated below.
ROS Integration
We use this ROS structure to link the whole system together. The intent_bot_apriltag could read videos and detect the April Tags IDs in the videos. It will combine with the pupillistener, which could track the user’s gaze, then output the object gazed at by the user. The output is combined with the output of speech_transcription then output the intended object to manipulation node. After receiving the intended object, the manipulator will plan to the object, and bring the object to the user.
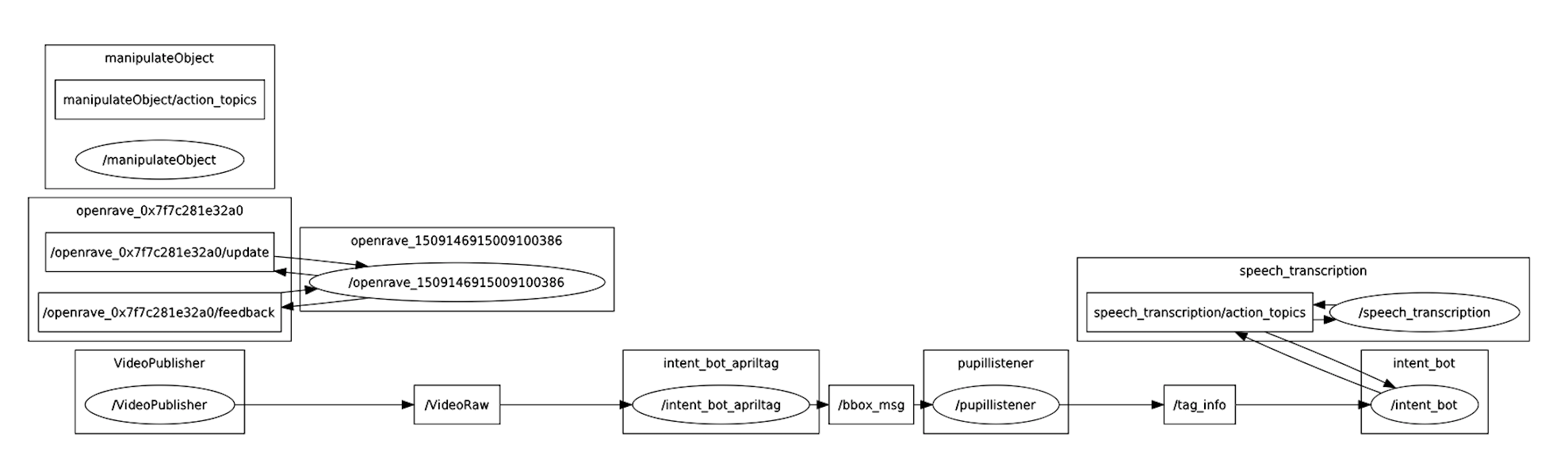
Subsystems Integration
This is a whole system demo of intent bot at CMU 50 year celebration exposition. The robot is able to recognize the user’s intent by speech and gaze. We received the speech command by the microphone and tracked the gaze by the gaze tracker. There were three objects on the table, two tomato soup can and a bottle. The manipulator could successfully pick up the intended object.
Subsystems Introduction
Manipulation
We use OpenRAVE on Mico Kinova(a.k.a ADA) and use PrPy to control ADA. PrPy is a python pipeline used by the Personal Robotic Lab. It includes OpenRAVE, TSR and TF. OpenRAVE could be used to build the environment for manipulator or calculate planning path for manipulator. TSR could be used to generate available grasping points and decide which one is the best one for the manipulator to grasp. TSR could store all the available points into TSR chain and pass the final decision to TSR list. TF could be used to keep track of the coordinate frame.
As shown in the picture below, TSR could calculate valid grasping positions and plan to a certain position we want. We use the collision-free planning, which could avoid any collision with the objects in the environment. Like the table and glass shown in the picture. We could also add invisible objects in the environment as walls to force the manipulator planning in a certain region.
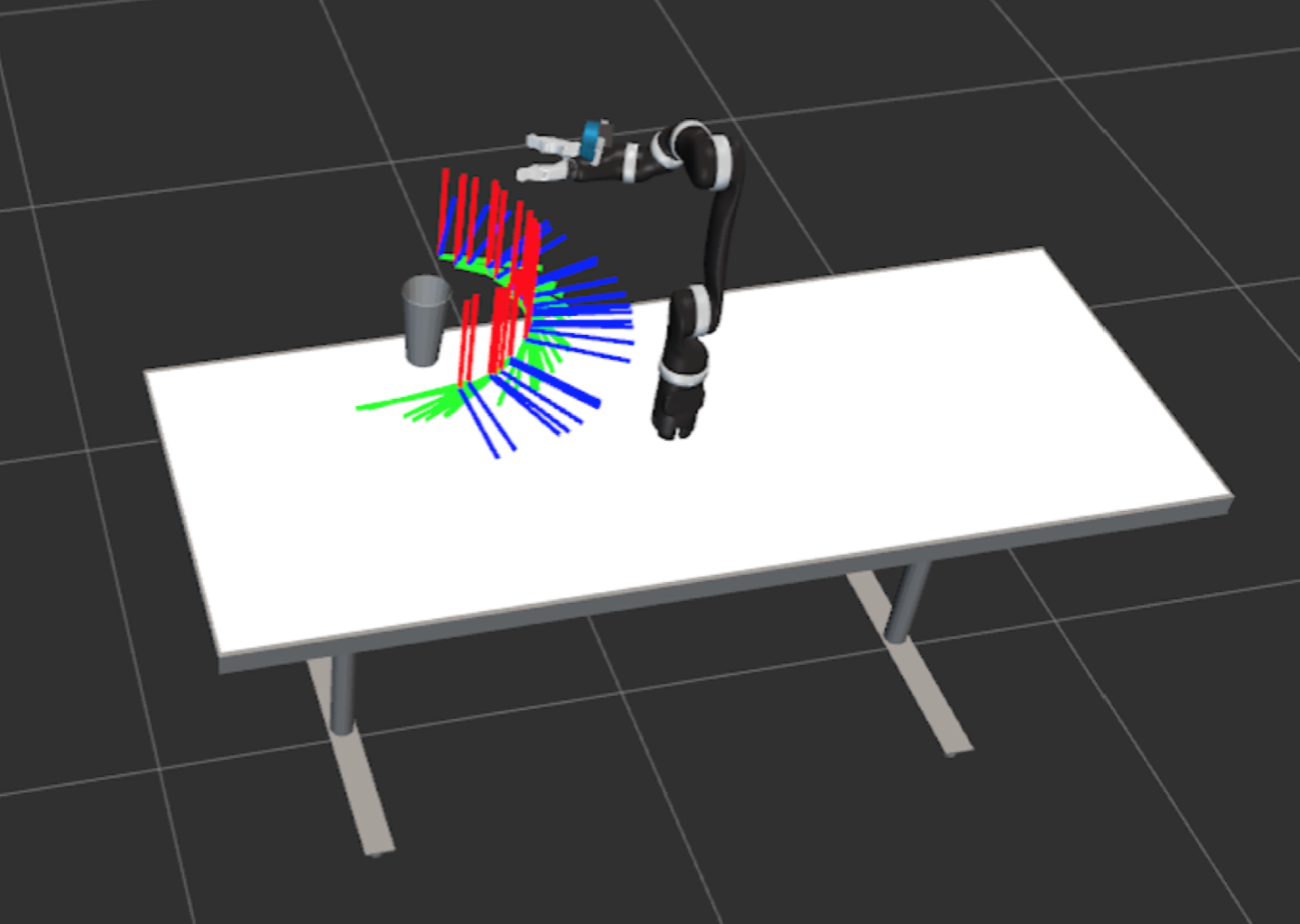
The manipulator is able to do the task planning to grasp the target object. In this video there are obstacles (white and green) between the manipulator and the target object(orange). The manipulator will move the obstacles out of the way and reach for the target object.
Intent Recognition
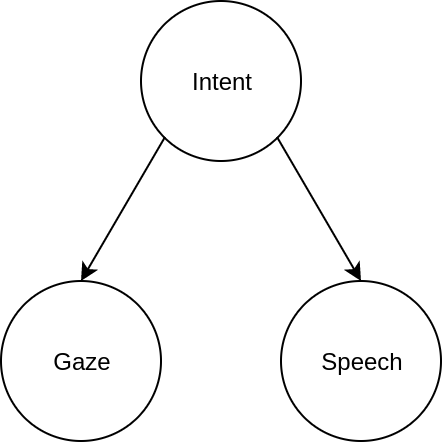
Intent prediction subsystem combines gaze information and speech to calculate the confidence of each objects in the view. Given the user’s speech and gaze information, the intent of the user can be predicted. The graphical representation of the bayesian network is shown in the figure below.
Speech Recognition
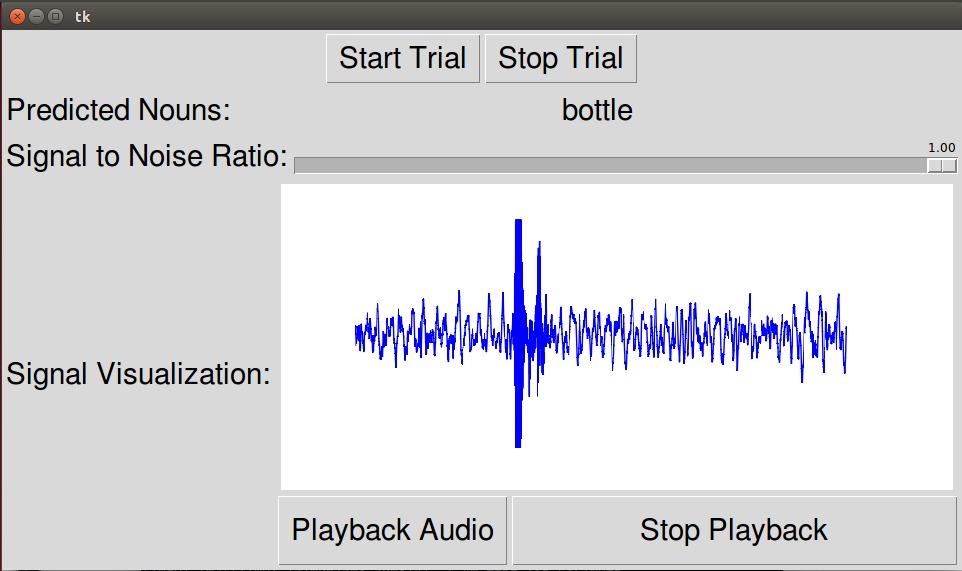
To get the speech based confidence, we first obtain the transcribed text using Google Speech API, then we used the Google Natural Language Processing API to obtain the list of nouns in the transcribed sentence, then we assign the speech confidence level to the individual nouns in the noun list. The speech confidence level is simply the confidence level of Google Speech API on the specific transcription. Figure 6 demonstrate the speech system in action. The speech system was able to detect the noun said in a speech and output the noun with the highest confidence, which is “bottle” in this case.
Gaze Recognition
For the gaze-based confidence, we used Pupil Lab gaze-tracking glasses to locate the area in the environment in which the user is looking at. The gaze location is shown as a red dot in the figure.


In the spring semester, we start doing data collection and the training of the gaze. The implementation detail is in the Gaze Subsystem.

Object and Environment Detection(FVE)
To identify the object that the user is looking at, we used AprilTag detection system. In AprilTag detection part, we use the video stream captured by the outward camera on Pupil Lab glasses as input and output the 2D bounding boxes of each object for gaze part. The algorithm work as follows: First, detection algorithm will calculate the position and orientation of each AprilTags that relative to the camera coordinate (red circles). Then, we hard code the model of each object as a cubic and the AprilTag is in the center of the top. Based on the model and AprilTag pose, we can get the position of each vertex in 3D space. Using camera intrinsic matrix, we can transfer the 3D position into 2D position in the image (pink circles), so that we achieve the 3D bounding box in image for each object (blue boxes). And 2D bounding box (green boxes) is defined as the smallest rectangle that can consist all 3D vertexes. The output of the AprilTag system is shown in the figure below.
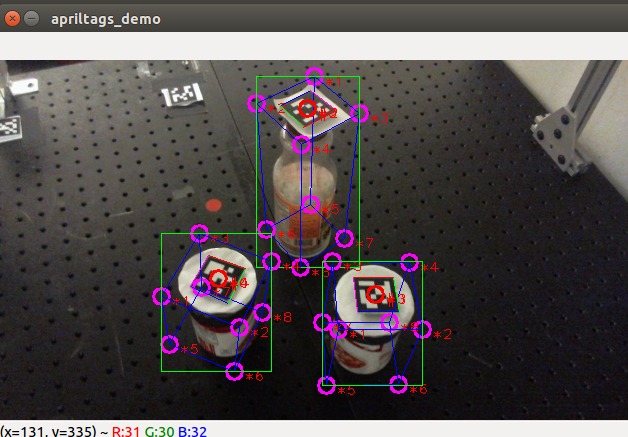
After obtaining the location of the gaze and the bounding boxes of the objects, the gaze based confidence can be calculated. Given the location of the gaze and the bounding boxes of the object, the gaze based confidence is calculated based on the distance from the gaze to the center of the bounding, as shown in the figure below.
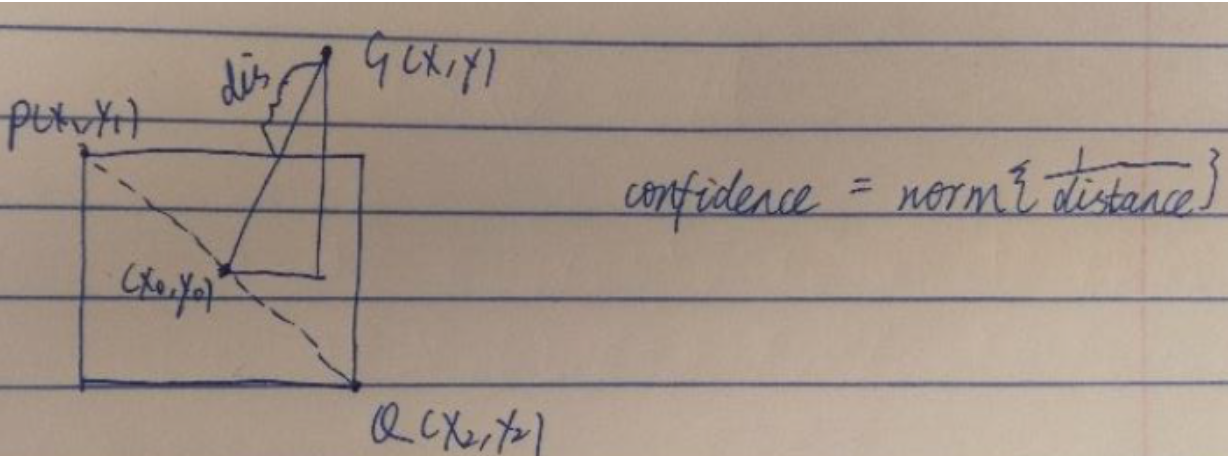
Object Localization
- Fix a Kinect above the table to detect objects and Reference AprilTags.
- Use Reference AprilTags to establish the coordinate and map the position of objects from Kinect coordinate to robot base coordinate.
