Behavior Planner
The behavior planner is a high-level level planner making decisions which are then further decomposed to low-level trajectories by a low-level planner and executed by the control system of the vehicle. In our case the behavior planner would issue high-level commands like accelerate, decelerate, lane change, maintain a constant speed.
The behavior planner is modeled as an RL (Reinforcement learning) agent, a DQN (Deep Q Network) is used in this case. This planner is trained over numerous episodes of varied types of the scenario it is meant to work in. For example, a lane change agent is trained to perform lane changes in varied traffic densities and varied NPC (Non-player characters) velocities.
The behavior planner takes a state vector representation as the input. The state vector representation which was used was a concatenation of the ego vehicle state and five closest NPC states into a single vector. The state contains the pose and velocity of the vehicle. The NPC states are represented in a coordinate frame relative to the ego vehicle.
During the design of the behavior planner, several alternatives were considered for the state representation and the neural network architectures. After testing out the results of the system, we finalized on the system described above. The following design options were considered for the behavior planner-
For the state vector,
- NPC states represented in the global coordinate frame.
- NPC states represented in a frame relative to the ego vehicle.
For the neural network,
- A set of fully connected layers, without ant state embedding.
- A set of shareable layers, to produce a state embedding, followed by a set of fully connected layers.
Based on multiple experiment results, we decided that for the state vector we chose option ‘2’ and for the neural network we chose option ‘2’.
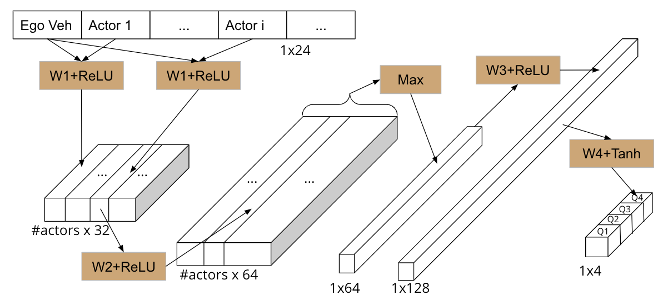
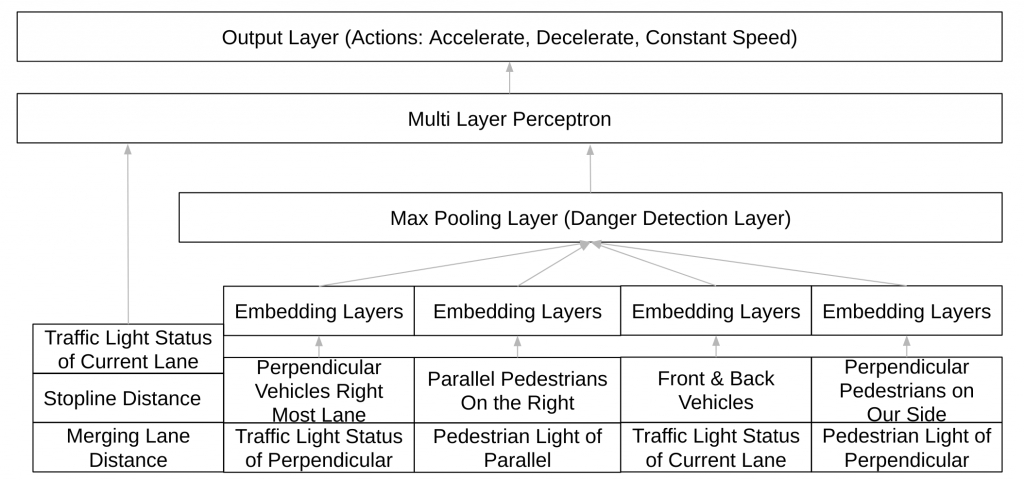
Network Architecture of the Behavior Planner
In the above figure, the neural network architecture used to implement the behavior planner is shown. The network has two parts in it- a set of shared layers which compute activations on each pair of NPC and ego vehicle state and a set of fully connected layers which finally produce the q-values for each action which can be taken.
In the first part of the network, the fact that the decisions which need to be taken are somehow related to the interaction of the NPCs with the ego vehicle is taken leverage of. Therefore, the first part of the network computes activations by considering pairs of ego vehicle and NPC states and then taking a max pool on these activations. This final sixty-four length vector can be considered as a state embedding for the deep Q network. The second part of the network is a set of layers with ReLU activations and a final layer with Tanh activation. The output of the network is taken as the q-values of the MDP being modeled by the network.
With the same algorithm, we have updated the neural network structures for the tasks we are undertaking, namely:
- Lane changing
- Lane Following
- Intersection negotiation
Network Structure for Lane Changing:
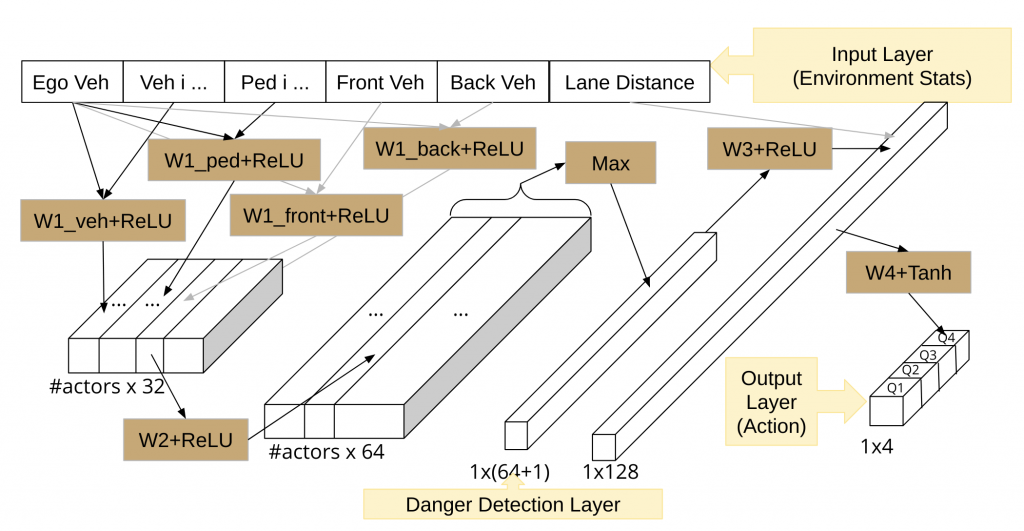
Network Structure for Lane Following:
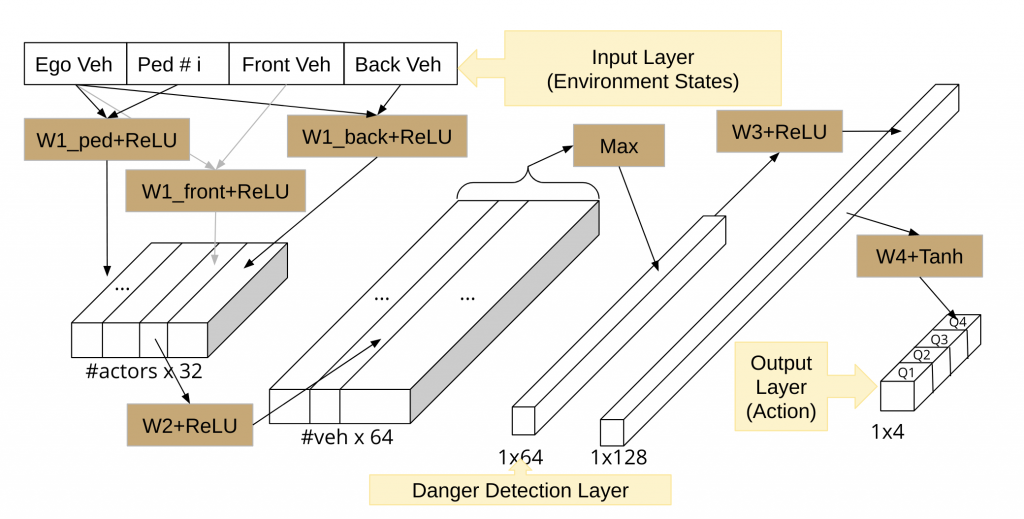
Network Structure for Go-Straight
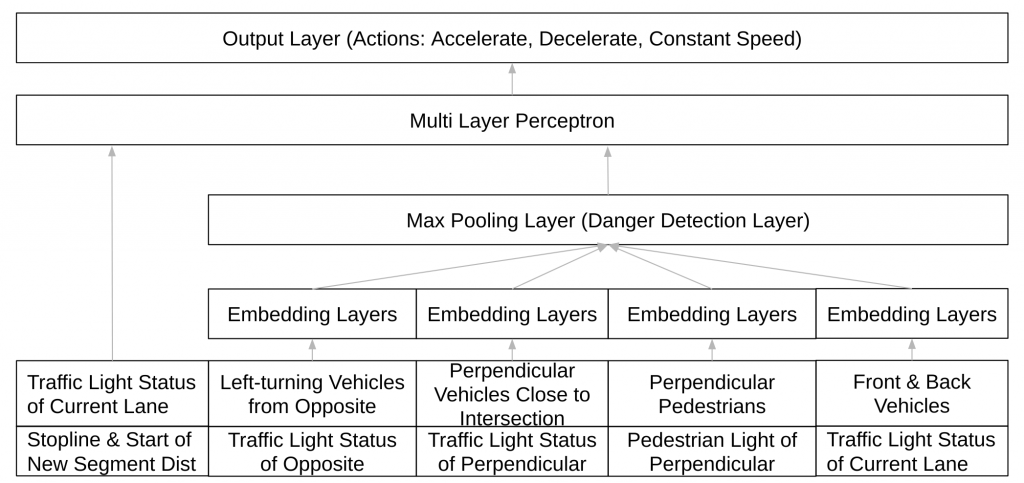
Network Structure for Turning Left
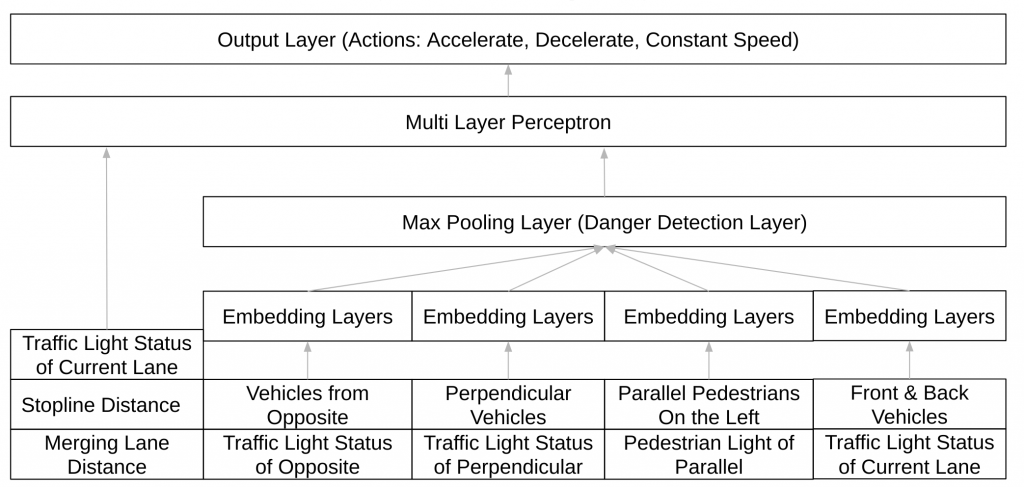
Network Structure for Turning Right
 Previous Post
Previous Post