As of 02/24/23.
Internal Milestone 1 – Achieved (02/22)
We set a deadline of 21st February for ourselves to achieve the Internal Team Milestone 1. We have been successful in achieving this feat. All the individual subsystems, namely, HRI, Navigation, and Manipulation are working independently. Our next Internal Team Milestone 2 is March 4th and by then, we intend to have a full-system integration. We are currently in the process of achieving that as we work on subsystem integrations first. Visually, this is what it looks like:
- HRI: The robot is able to register voice commands, and respond to them. The video calling API Agora has been integrated as well. The user is also able to tele-operate the robot by being able to control the robot base’s movement and the arm’s movement with a very simple game-like UI.
- Navigation: Within the AIMakerSpace, for which a 2D Map has been collected, the robot is able to navigate from one point to the other based on the input given for destination location. The robot also positions itself in front of a table in a way that it can extend its arm and grab the object.
- Manipulation: We are able to perceive objects in the environment as obstacles, and also as objects of interests which the user might want to retrieve. We are able to predict grasp poses on the object and the planning algorithm helps us pick and place them with a single-joint movement.
Progress so far in images and videos…
Eyes
GGCNN
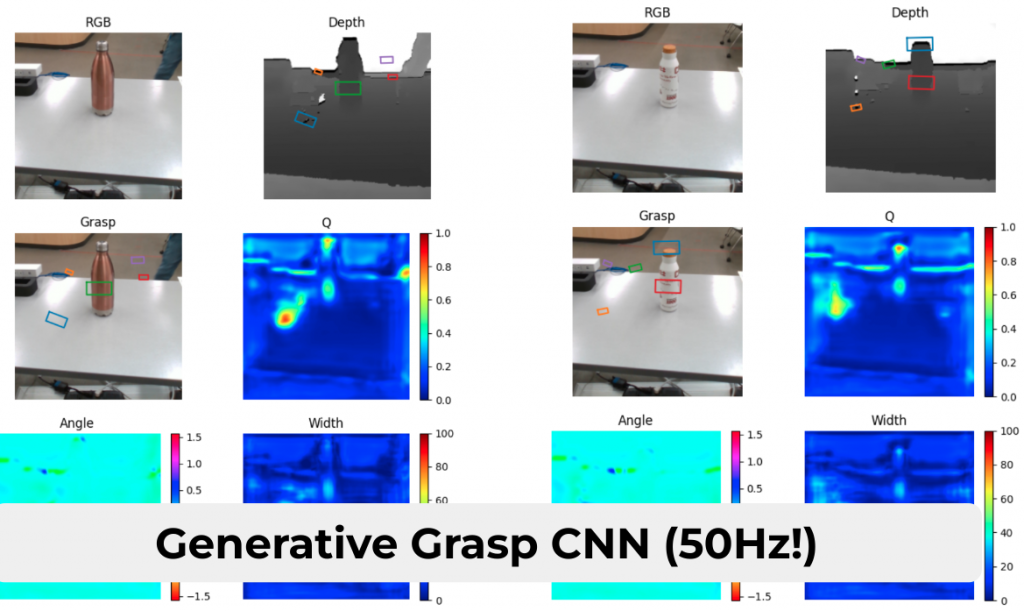
GraspNet

Video Call
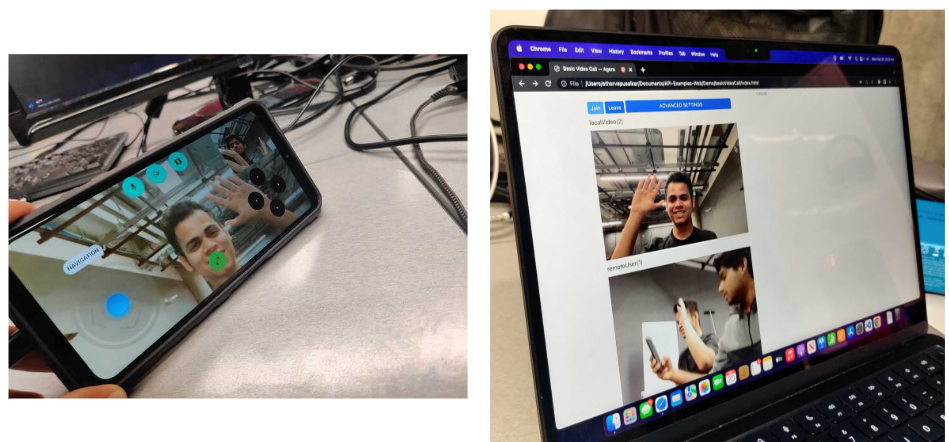
Tele-op

Manipulation (2x)
If video doesn’t work, watch it here.
Internal Milestone 2 – Achieved (as of 04/07)
In addition to IM 1, this is where the system stands right now. Unless specified explicitly, assume that no functionality was removed or appended other than the descriptions below.
HRI: ChatGPT has been integrated with the system. Instead of giving the typical long responses, it has been conditioned to first identify whether the user input requires a verbal response (“How is the weather?” “What is the capital of the US?”) or an action (“Fetch me water bottle”), and then proceed with either a brief verbal acknowledgement or a full-on response, depending on the user’s ask. The system can also provide non-verbal feedback using the eyes based on what kind of task-execution stage the system is at.
Navigation: The system is able to successfully avoid obstacles and follow a trajectory around them in order to reach its destination. There have also been initial experiments with RTAB-Map for 3D Navigation.
Manipulation: The system is able to predict whether the grasp is successful or not and provide feedback to the Perception pipeline.
Progress so far in images and videos…
Non-verbal feedback
If video doesn’t work, watch it here.
RTAB-Map in Simulation
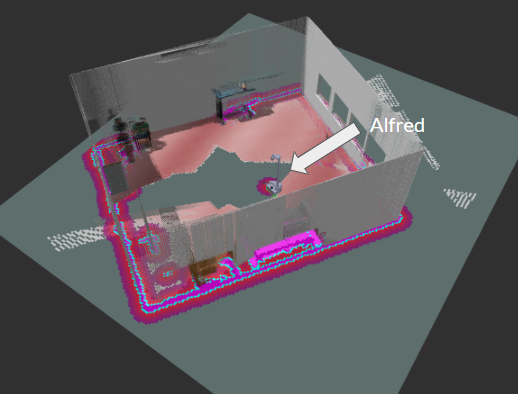
RTAB-Map in AIMakerSpace

Obstacle Avoidance
If video doesn’t work, watch it here.
Grasp Recognition
For Bottles and Box:
If video doesn’t work, watch it here.
For markers:
If video doesn’t work, watch it here.
Spring Validation Demonstration
The time between IM2 and SVD was primarily spent on fixing bugs in subsystems, integrating all subsystems, improving the reliability of the subsystems and overall systems, and, biggest of all, dealing with hardware problems. We have gone through 3 iterations of robot changes with the help of Prof Oliver Kroemers’ robots that were not being used.
The final status of each subsystem is described below:
Overall System Integration
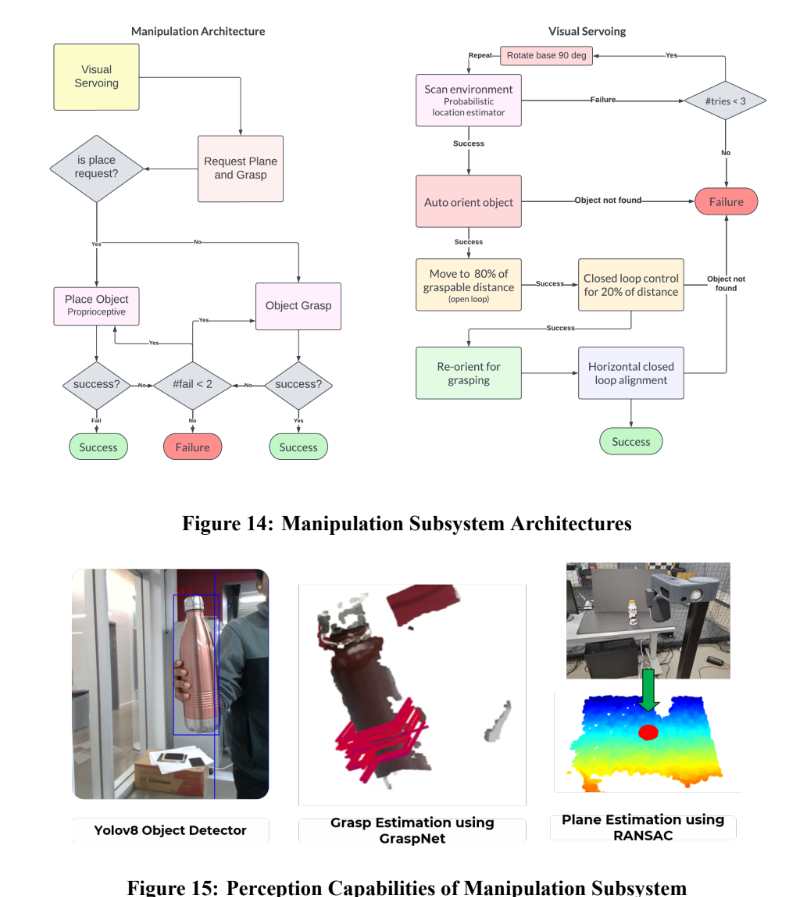
Our overall software architecture comprises several different subsystems operating in tandem, coordinated by 4 different layers of finite-state machines. {Level 1:} A high-level mission planner coordinates the global status of tasks that are executed. {Level 2:} Each subsystem has its own local FSM that is used to execute sub-tasks. {Level 3:} Our manipulation subsystem has several complex algorithms that require their own FSMs executing within Level 2 FSMs. {Level 4:} All of our subsystems are orchestrated by action servers which are based on a low-level FSM.
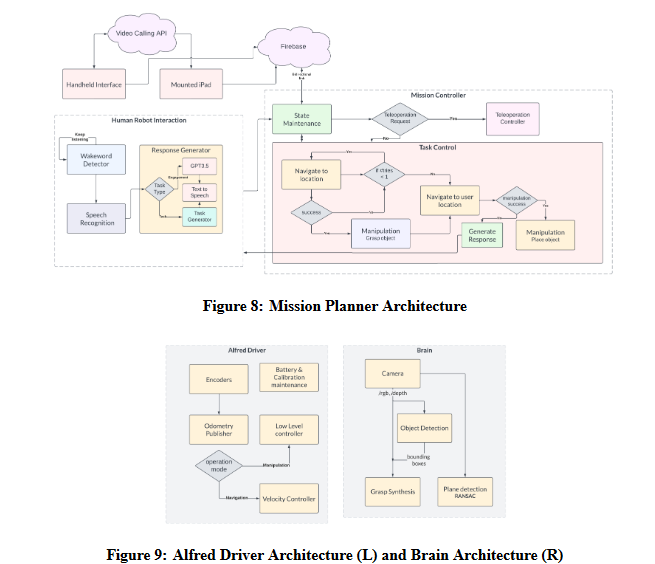
Human Robot Interaction
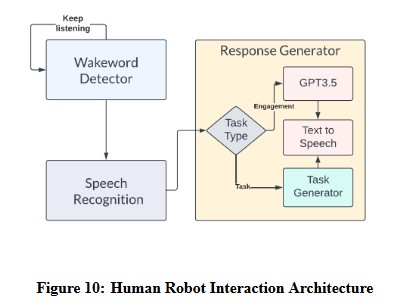
The Human-Robot Interaction (HRI) subsystem enables the robot’s Speech Engagement and Telepresence capabilities. The Speech Engagement subsystem includes Picovoice for trigger word detection, Google Cloud’s speech-to-text API for speech parsing, and DeepMind’s Neural2 API for life-like voice synthesis. ChatGPT is also integrated to handle social engagement requests. The trigger-word detector is always active, and when the user says the trigger word, the speech-parsing API is activated. If the user’s request is for a pick-and-place command, the mission planner performs task allocation to identify the desired object to be placed. If the user’s request is for a social-engagement command, the mission planner delegates the task to ChatGPT to generate a response. Finally, the robot gives feedback to the user through a speech command that addresses their request.
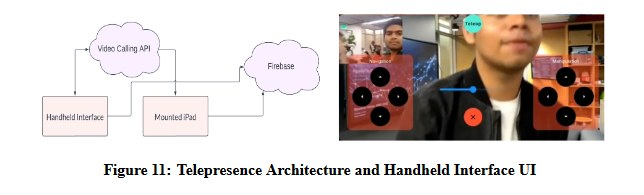
The HRI subsystem’s telepresence capabilities include teleoperation through a handheld interface UI and video calling with the Agora API. Firebase cloud service is used for wireless communication, and an iPad is mounted on the robot’s head to display its face and video calling screen. } shows its functioning.
Navigation

The navigation subsystem is responsible for moving the robot in the operating environment from an
initial location to the desired location of the object, and back to the initial location (where the object is
to be placed). It is implemented in Python and C++ using the ROS Noetic platform. At a high level, the
navigation subsystem performs functions such as Mapping, Localization, Motion Planning, Dynamic
Obstacle Avoidance, Controls, and Actuation.
The development of the navigation subsystem started with the generation of a 2D map of the AI
Maker Space (test environment). This was generated using SLAM with the help of the gmapping
package in ROS. Given that the position of the Stretch RE1’s 2D Lidar is at knee-height, several static
objects in the environment, such as tables, were not included in the initial map generated. In order to
prevent the robot from planning paths through these regions, the 2D map was manually edited using
a software called GIMP. Specifically, regions, where the robot should not traverse, were marked as
unknown regions (grey color) in the map.
For localization, we used the Adaptive Monte Carlo Localization algorithm, implemented in the
amcl package in ROS Noetic. This algorithm would use the robot’s real-time odometry and lidar data
for the prediction and update steps, respectively. For robot path planning and controls, the movebaseROS library was used. We used Dijkstra’s algorithm (Navfn ROS) for global path planning and the Dynamic Window Approach (DWA) algorithm for local path planning and controls. While these planners usually generated feasible paths through the test environment, there were times when the robot would struggle to navigate around an obstacle. In these situations, the robot would trigger its recovery behaviors. The recovery behaviors used by our navigation subsystem were Clear Costmap Recovery, Rotate Recovery, and Moveback Recovery. The Moveback Recovery behavior is a custom plugin developed by the team that commands the robot to move back by a set distance and replan a path, in cases where the other two recovery behaviors fail. Additionally, we extensively tuned ROS parameters in Costmap, Planner, and AMCL packages to optimize the robot’s performance in the test environment.
Manipulation
Our manipulation subsystem handles both pick as well as place requests. The manipulation subsystem begins execution once the navigation subsystem has completed its task. Once a pick request is issued to the subsystem, we execute tasks in sequence as described in our architecture:
- Visual Servoing: The visual servoing algorithm is responsible for finding the object of interest in the environment and automatically aligning the robot to a graspable position. Each part of the algorithm is described below:
- Scanning: Using the head camera assembly (Intel RealSense D435i) on the robot, we pan the camera across the environment while parallelly detecting all objects in the environment using the Yolov8 object detector.
- Visual Alignment: Once we estimate the location of the object, we perform a sequence of closed-loop control steps that uses visual feedback in order to align the robot within a maximum graspable distance threshold.
- Recovery: We employ several recovery schemes in order to ensure that the robot doesn’t reach an irrecoverable state.
- Grasp Generation: We developed three methods for grasp generation, namely GraspNet, GGCNN, and Median Grasp.
- Plane Detection: We employ a plane detection algorithm based on the RANSAC scheme in order to estimate the plane from which an object is picked.
- Motion Planning and Control: Our current system employs a basic control pipeline that does not consider obstacles within the workspace of the manipulator.
- Grasp Success Validation: Our platform’s Stretch Gripper has a parameter called “effort”. We verified this hypothesis by collecting data, plotting graphs, and analyzing gripper width v/s effort values. We trained a Logistic Regression model on this data.
Our placing pipeline is very similar to our picking pipeline. When a place request is received, we utilize a simplified version of our visual servoing module in order to align the robot with the table. We then use the RANSAC algorithm in order to estimate the plane of placing the object and estimate a placing location on the surface of interest. Post this, we use a contact sensing-based placing scheme that allows the robot to automatically sense when the object has been placed on the table and release the object from the end-effector.