System Requirements
| Functional Requirements | Performance Requirements | Justification/Assumption |
| Receive commands from the user: preset speech primitives/handheld interface | Word-error rate <=10% Latency for control commands <5s | Robot should understand what the user wants it to do |
| Perform basic (pre-defined) social engagement with user | Fallback rate: <20% | User chats with the robot |
| Localize itself in the environment | Error threshold: <25 cms | Real-time visual data and precomputed map available |
| Plan and navigate through the pre-mapped environment | Plan global path to desired location within 2 minutes Navigate at a speed of 0.4 m/s | Assuming latency in receiving user input, obstacle detection, path planning, and goal location is 20m away from the robot. |
| Autonomously avoid obstacles in the environment | Avoids 80% of the obstacles in range | Assuming objects lying in the FoV of visual sensors |
| Detect objects for grasping | mAP >= 80% for 10 object categories (e.g bottle, remote, medicines etc) | Predefined class of objects are placed in expected and appropriate lighting. |
| Manipulate predefined objects to/from planar surfaces at known locations in the environment | Greater than 70% successful picks and places | Manipulation algorithms are tuned beforehand for our set of objects. |
| Allow approved operators to teleoperate the robot | Communication latency <5s | Assuming connection initialization and transmission delays and command interpretation time. |
| Provide user with robot metrics and video feed of the robot on a handheld interface | Latency: <2s Resolution> 720p | Robot should provide a real-time experience to the user |
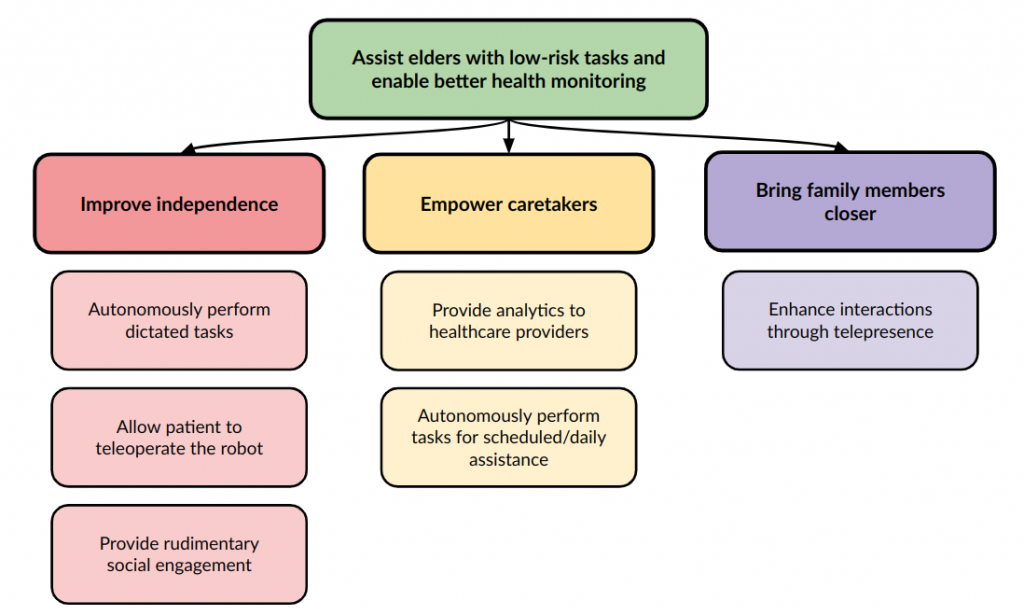
Objectives Tree
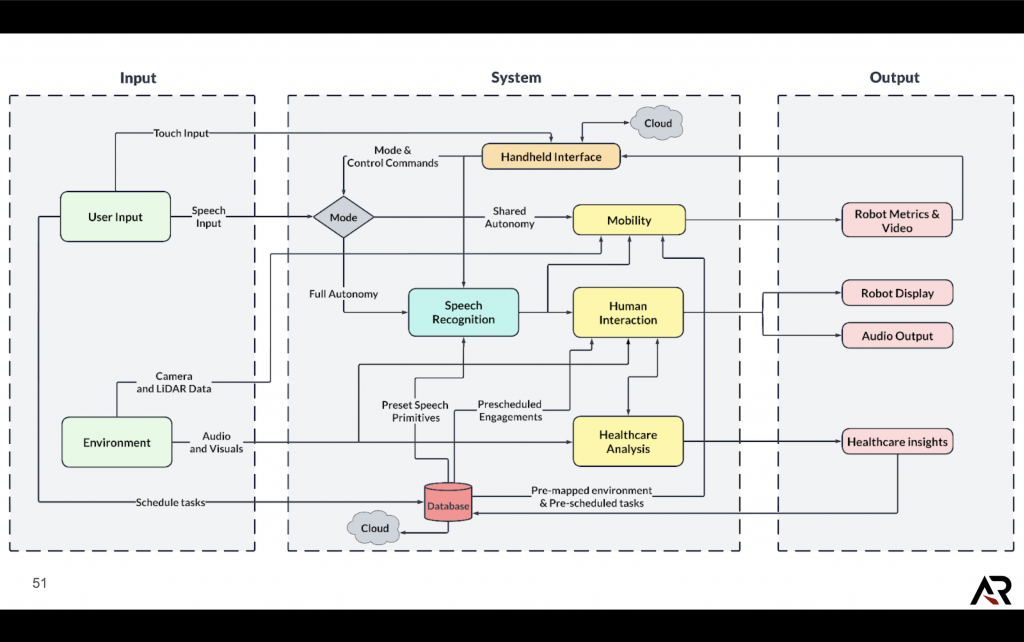
Functional Architecture
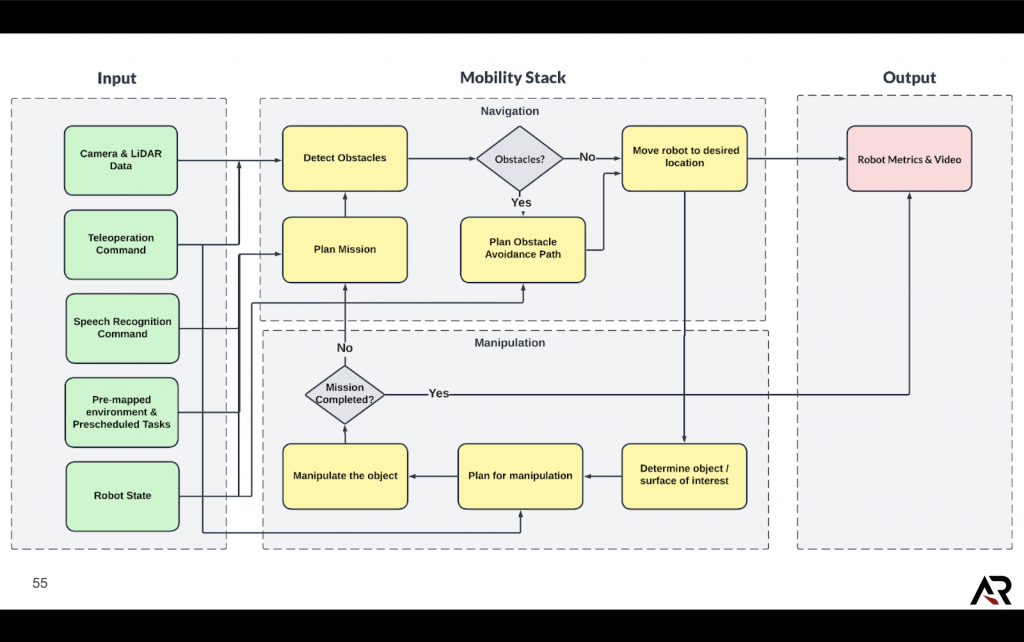
Mobility
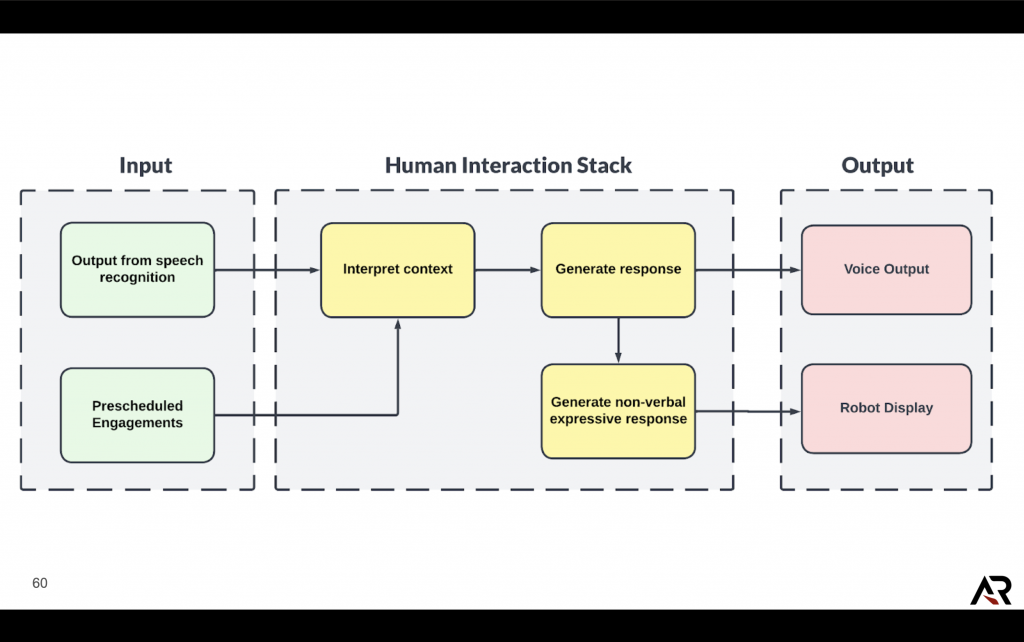
Human-interaction Stack
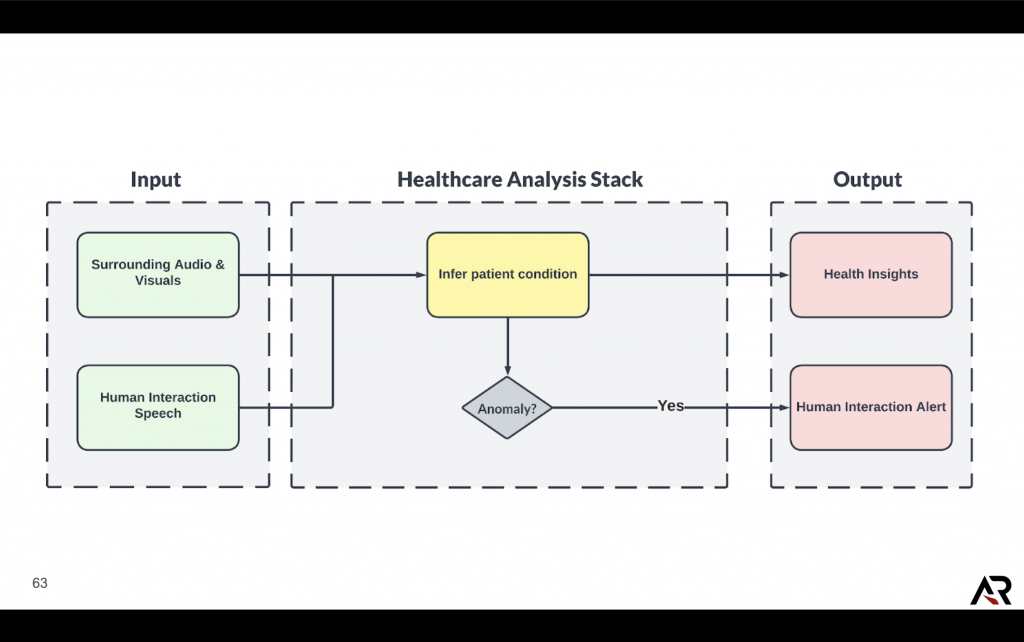
Healthcare Analysis Stack
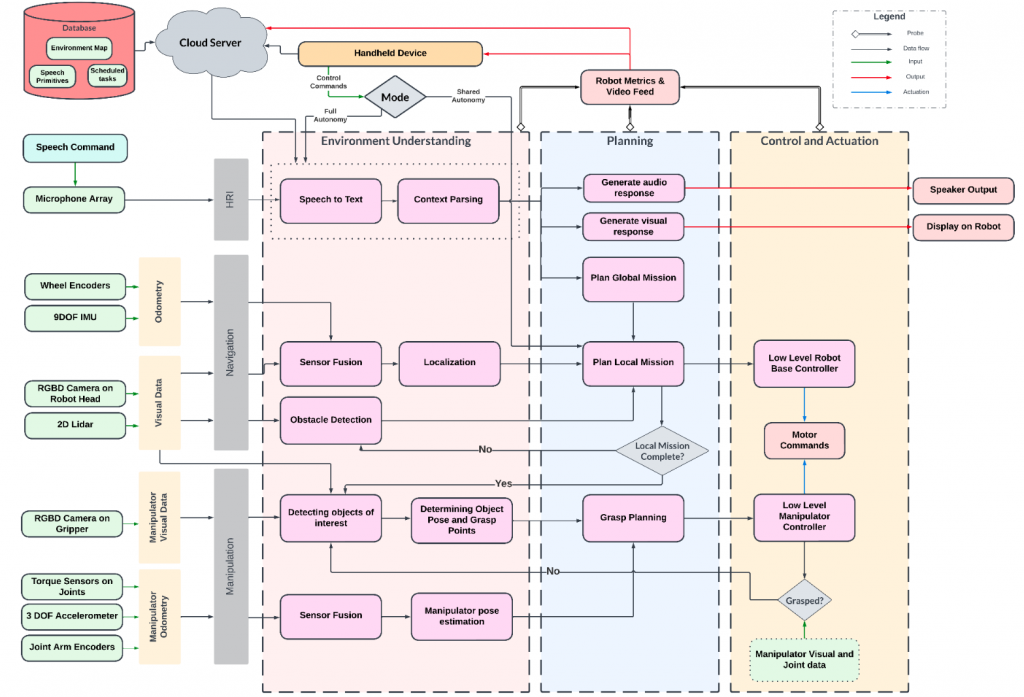
Cyberphysical Architecture
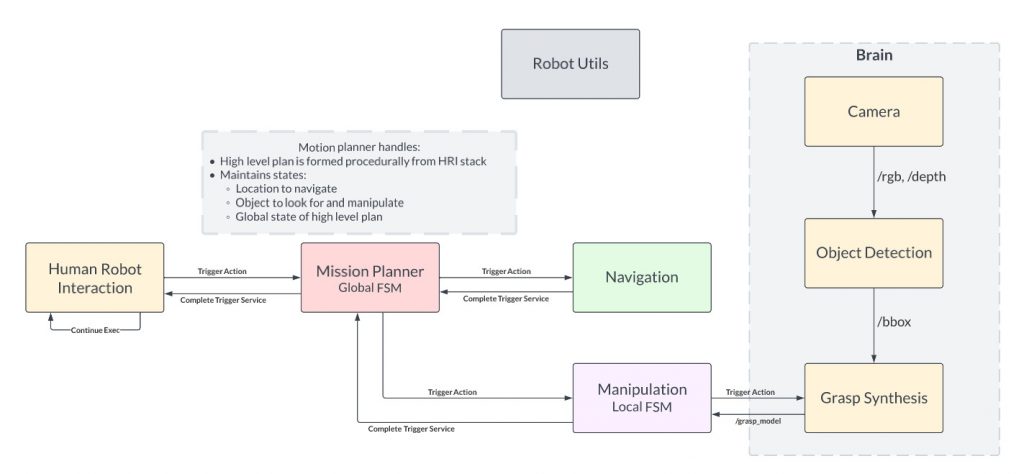
System Design

Technical
User Standpoint
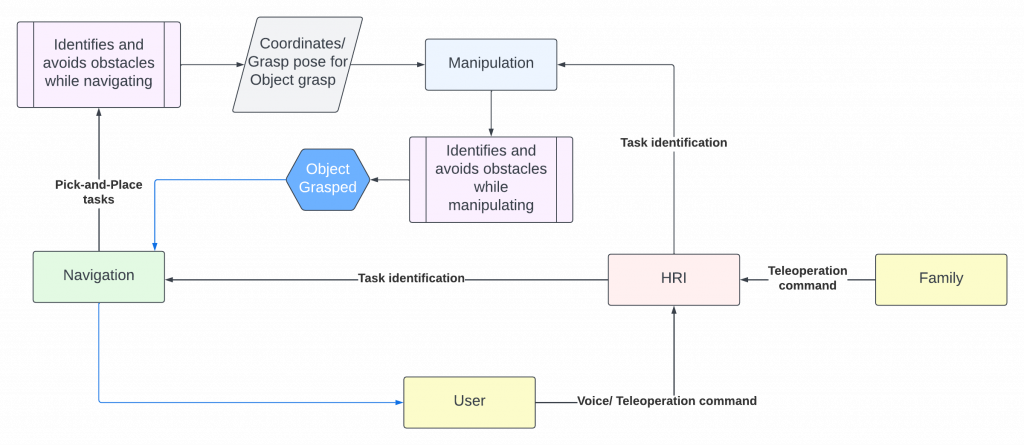
The system works as follows:
Voice-based tasks:
- The user (patient) gives a voice command input like “Hey Alfred!”.
- Alfred starts listening.
- User says “Get me that bottle of water.”
- Alfred understands that this is a pick-and-place task and it needs to traverse to a set location to fetch the requested item.
- Alfred navigates while taking care of not colliding with the obstacles in the environment.
- Alfred reaches the table on which the object of interest is kept, positions itself in a way that its arm can extend to grab the bottle.
- Alfred lifts and extends its arm, grabs the bottle, retracts the arm, stows it, and proceeds safely back to the user without colliding with any other obstacle.
- Alfred places the bottle next to the user on the table.
Family teleop:
- Family gets on a video call with the user (patient) via the screen on top of Alfred.
- Family requests control to the robot.
- User approves it.
- Family teleoperates the robot, draws the blanket on top of the user, checks out the surroundings, and feels closer to the user.
HRI
Speech Recognition
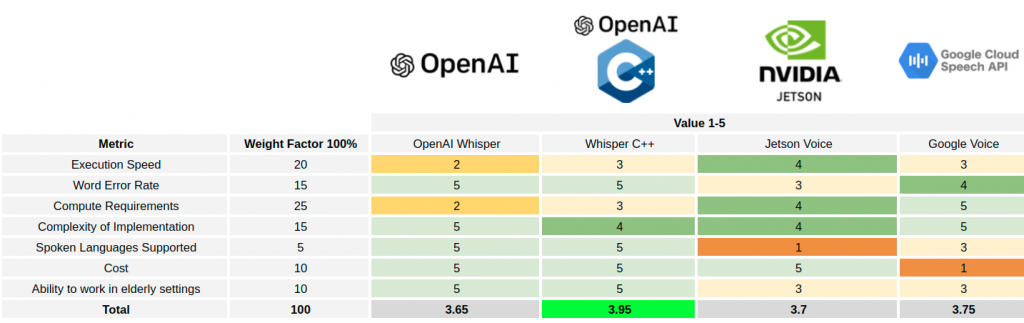
We had initially used whisper C++ for recognizing user’s speech input. Wakewords like “Hey Alfred!” make it possible for the robot to identify when it needs to start listening for commands from the user. Based on the input, the pipeline decides which act to perform using its list of task-templates. However, due to heavy constraints on the compute on our robot, we have shifted to the google cloud speech API.
Video Calling API
We use Agora for our video call functionality. The video feed shows up on the tablet mounted atop the robot. The feed you get can be observed under Teleoperation below.
Teleoperation
The app takes in input from the user through the mobile application’s UI. This input is pushed in the form of commands onto Firebase. The robot reads these commands and performs the functions requested by the user (In our case, the family back home). Our UI can be seen in the image below:

Non-verbal feedback
We have eyes on the robot that provide non-verbal feedback. We intend to integrate this with a head-rotation that allows the robot to look in the direction of where the voice is coming from. We have gone through several iterations of the design. The current design is below:
V2.


To check out the visual implementation of the subsystems below, you might want to go through this blog here.
Navigation
The navigation stack in our system is crucial to two functionalities:
- To reach the desired location to perform the pick-and-place manipulation tasks.
- To perform the function desired by the teleoperation input from the user.
Perception
We pre-map the environment and feed that as reference for our robot to understand the environment it’s supposed to navigate in. For identifying obstacles in the periphery and localizing the robot during navigation, we use the LiDaR mounted atop the robot base.
Planning and Controls
Once the localization is achieved, the global planner plans the trajectory of the robot to its destination. En route to the destination point, the local planner DWA corrects any errors in trajectory and also avoids obstacles. We tune the parameters for the AI makerspace.

Manipulation
The manipulation stack in our system is crucial to two functionalities:
- To perform the pick-and-place manipulation tasks.
- To perform the function desired by the teleoperation input from the user.
Perception
For detecting object of interest in the environment, we use YoloV8. It generates bounding boxes around objects as shown below:

We use this info to generate a precise grasp pose using GraspNet. This is done so that the end-effector knows how to execute the grasping task. You can see an implementation of multiple grasps on multiple objects in the image below:

Planning and Controls
Prior to grasping, we automatically orient the robot such that the object is graspable. This is done using a visual serving algorithm that uses several closed-loop controllers, tightly coupled with a vision based probabilistic estimator to align the robot with the object of interest.
Once we know the robot is, where the object is, and how we’re supposed to grasp it, the system uses a go-to-planner in which the 3D coordinates are fed in as an input so that the planner can proceed in a single-joint trajectory to reach the object of interest. The object is lifted to avoid drag along the surface. The placing pipeline uses contact sensing in order to place the object of interest on a table.
