Design Brainstorming
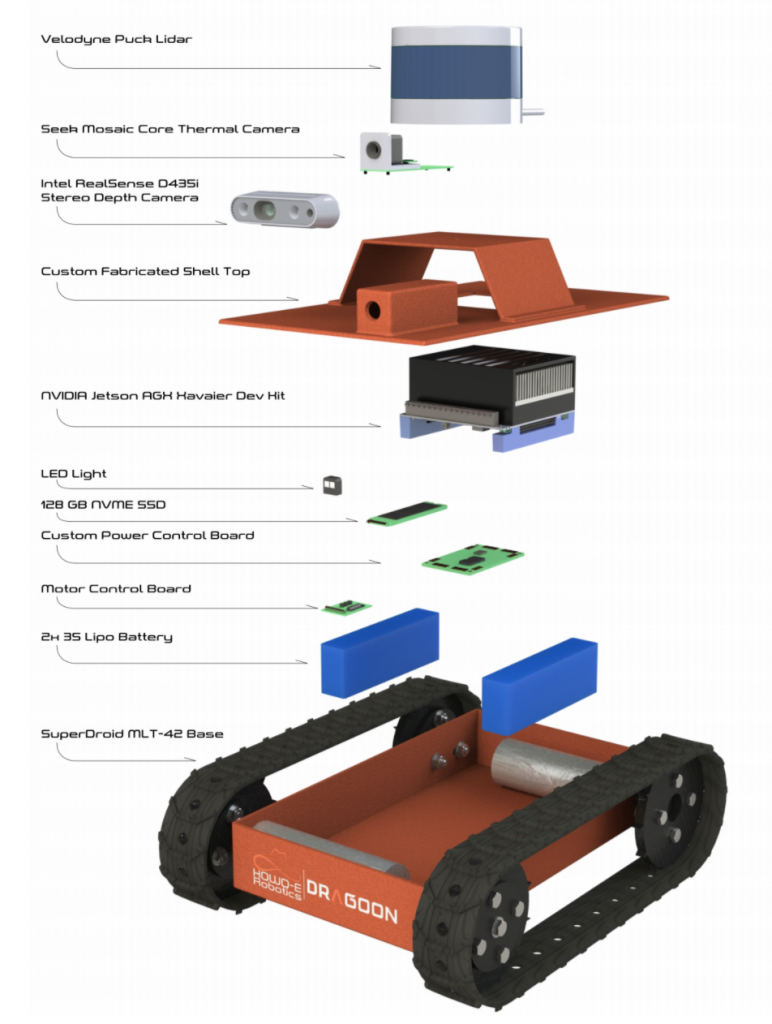
First iteration of robot design
Preliminary layout of robot
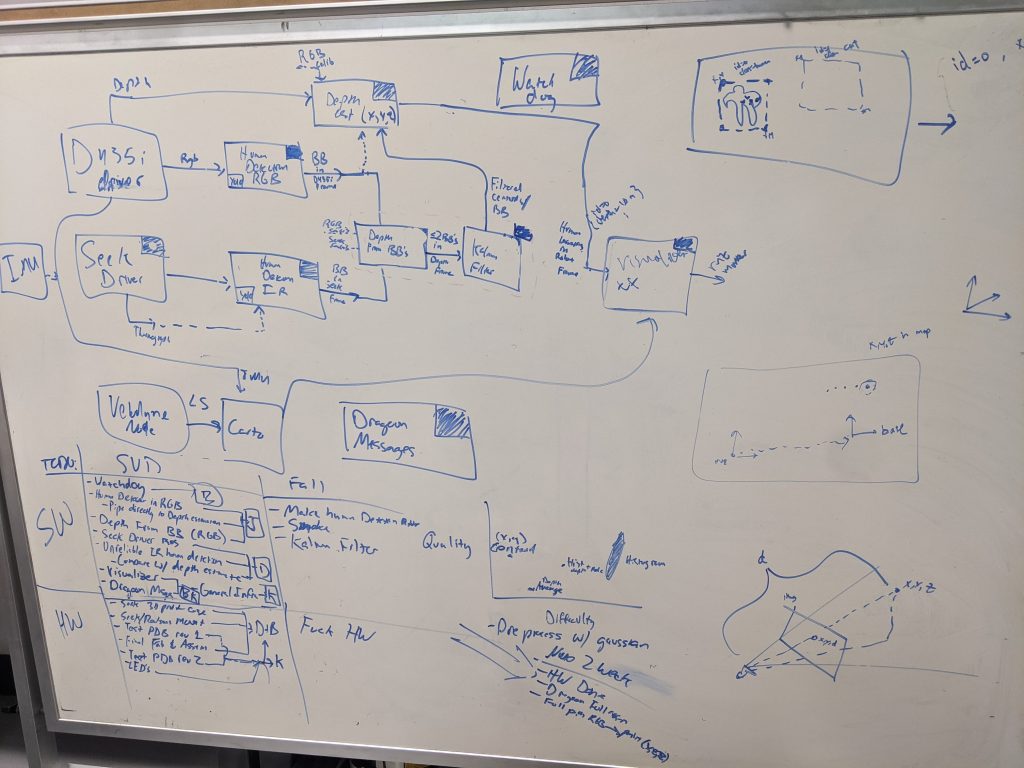
Software brainstorming
Drawings, Schematics and Datasheets
Electrical
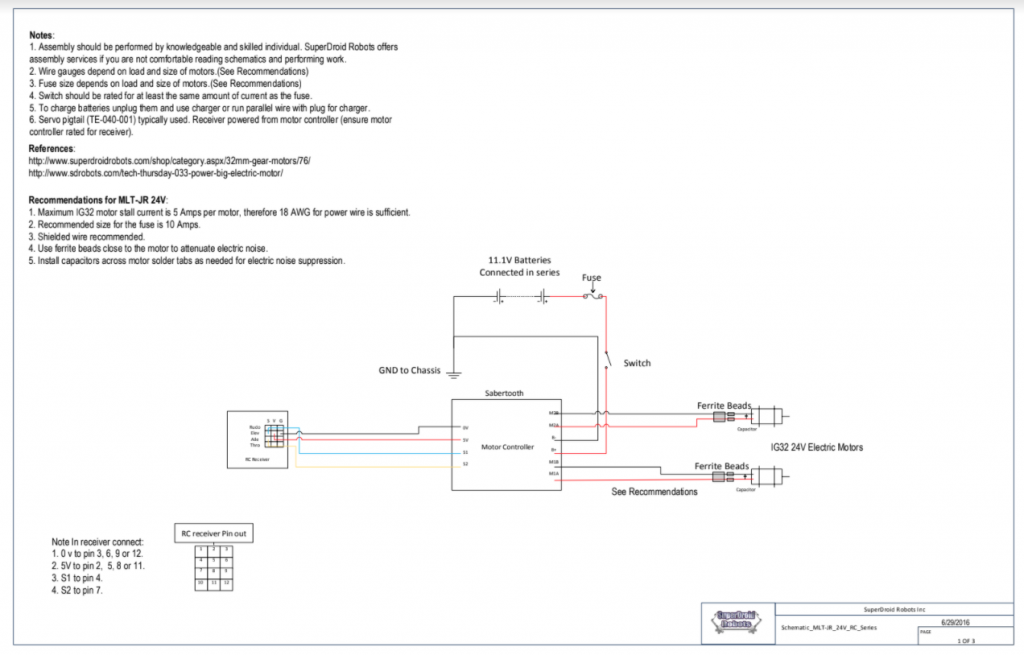
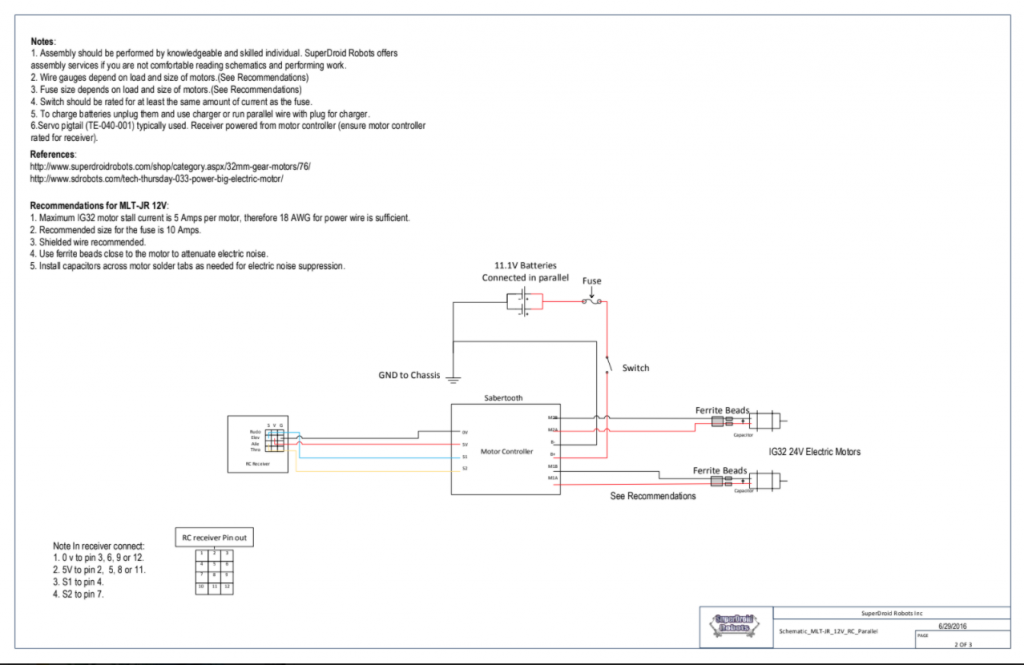
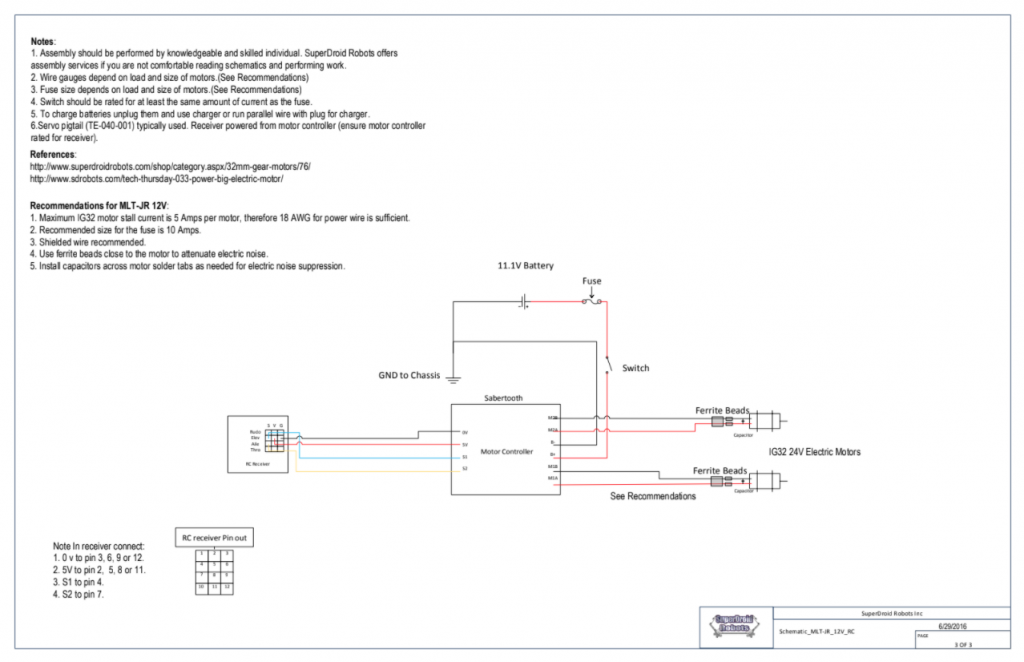
Schematic Circuit Diagrams for Dragoon’s Motors
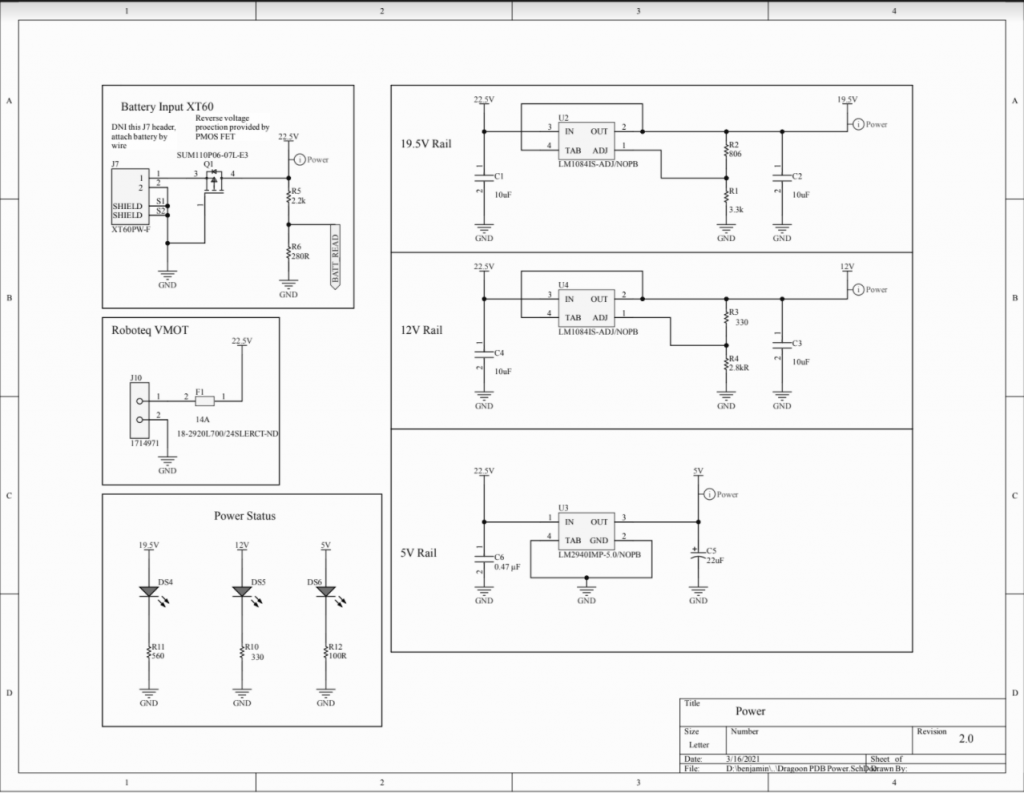
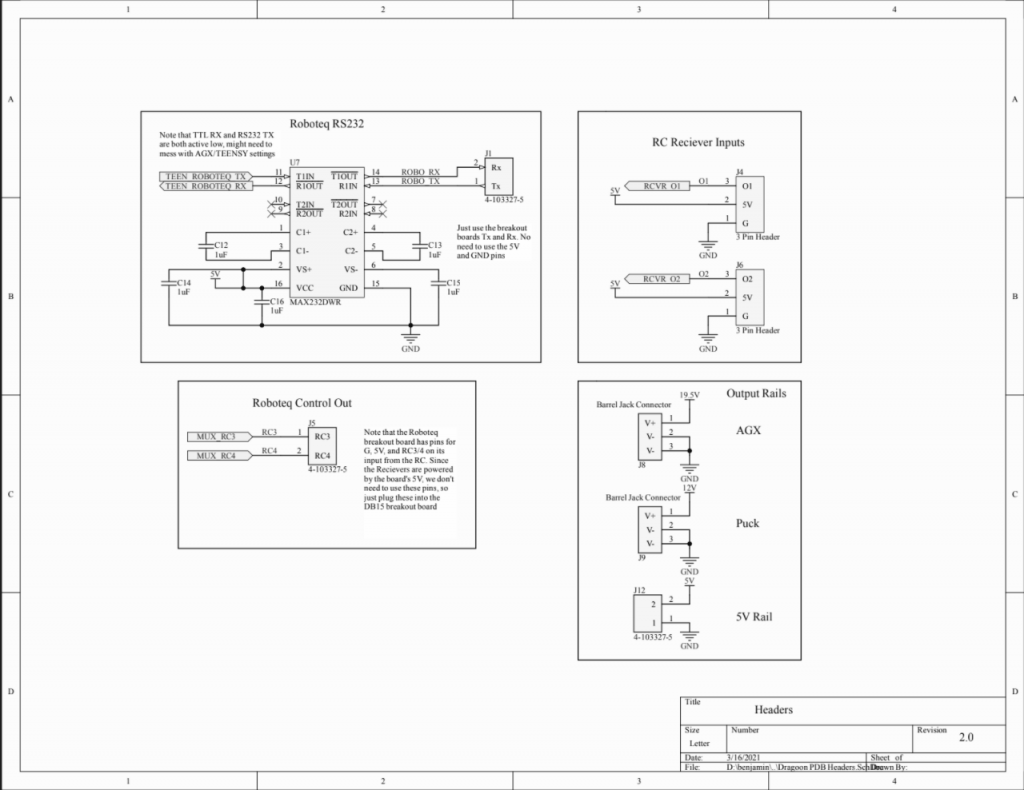
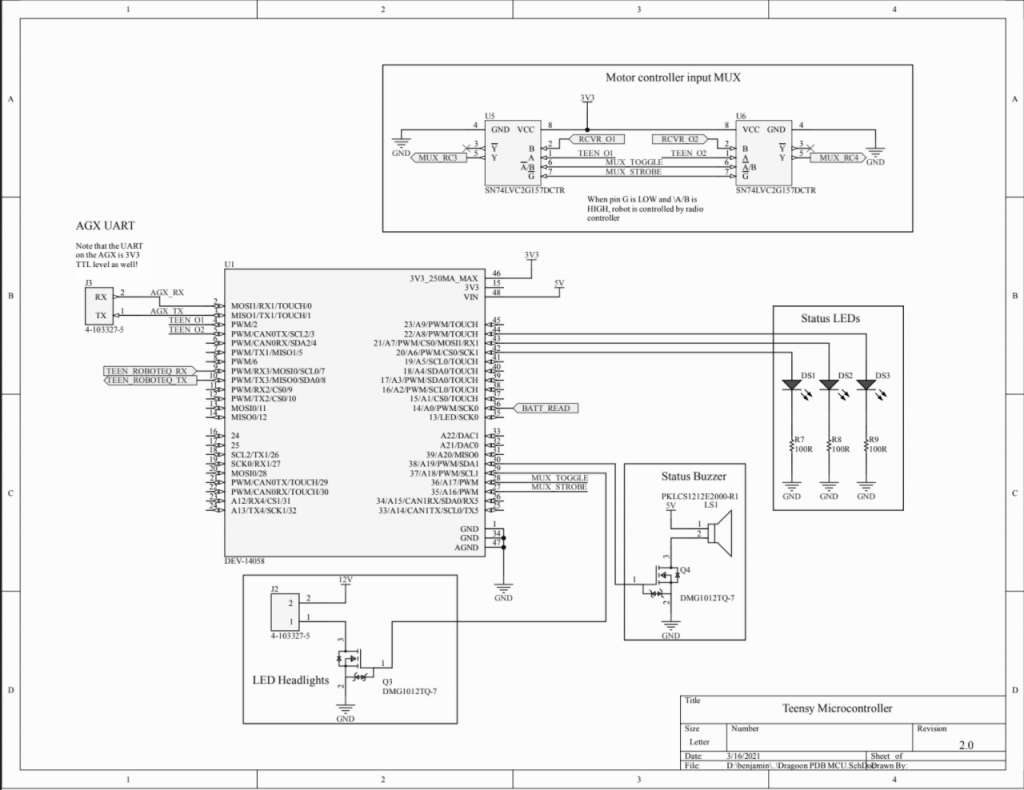
PDB V2 Design Files
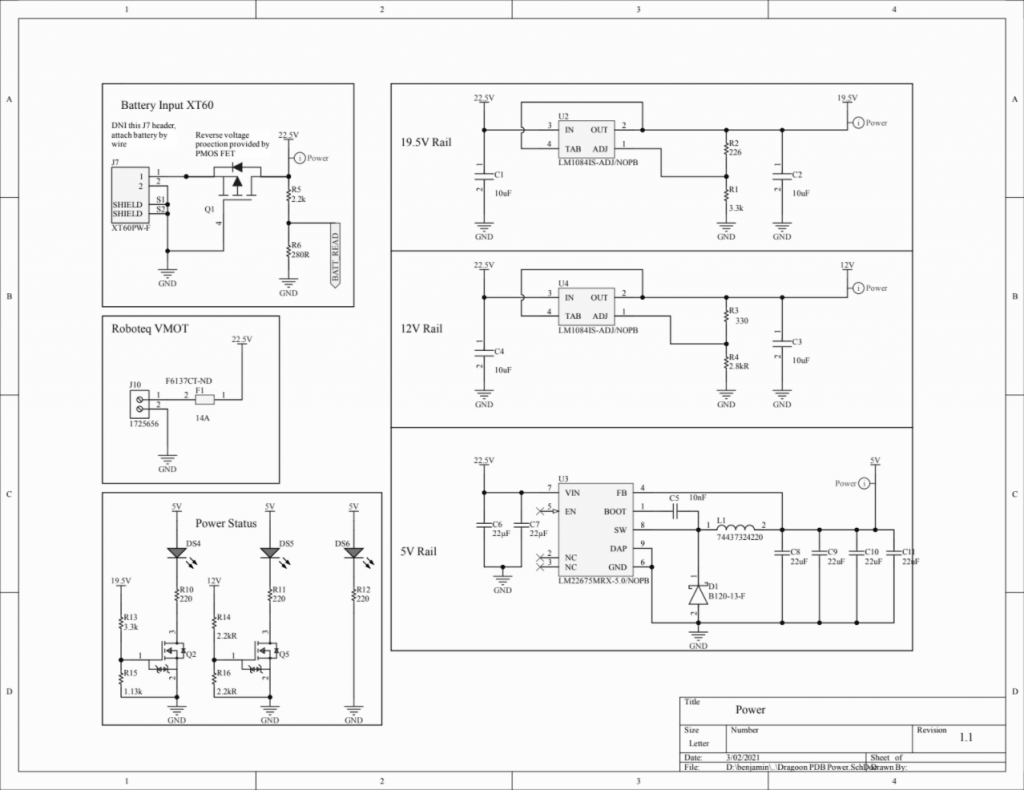
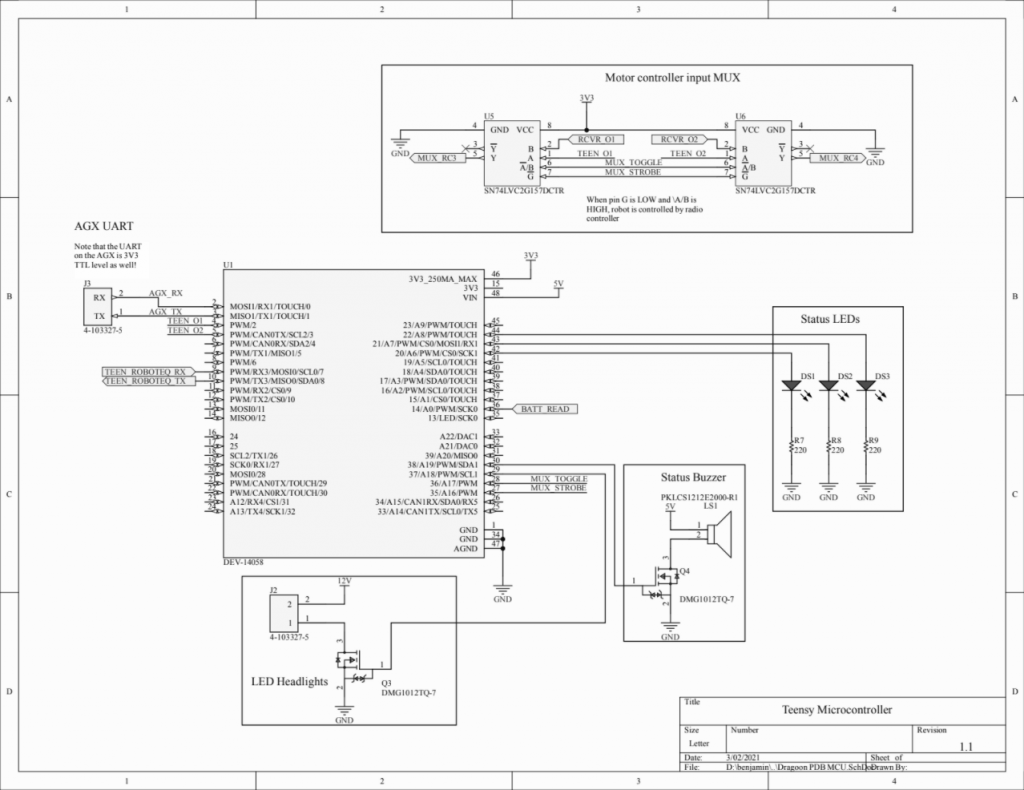
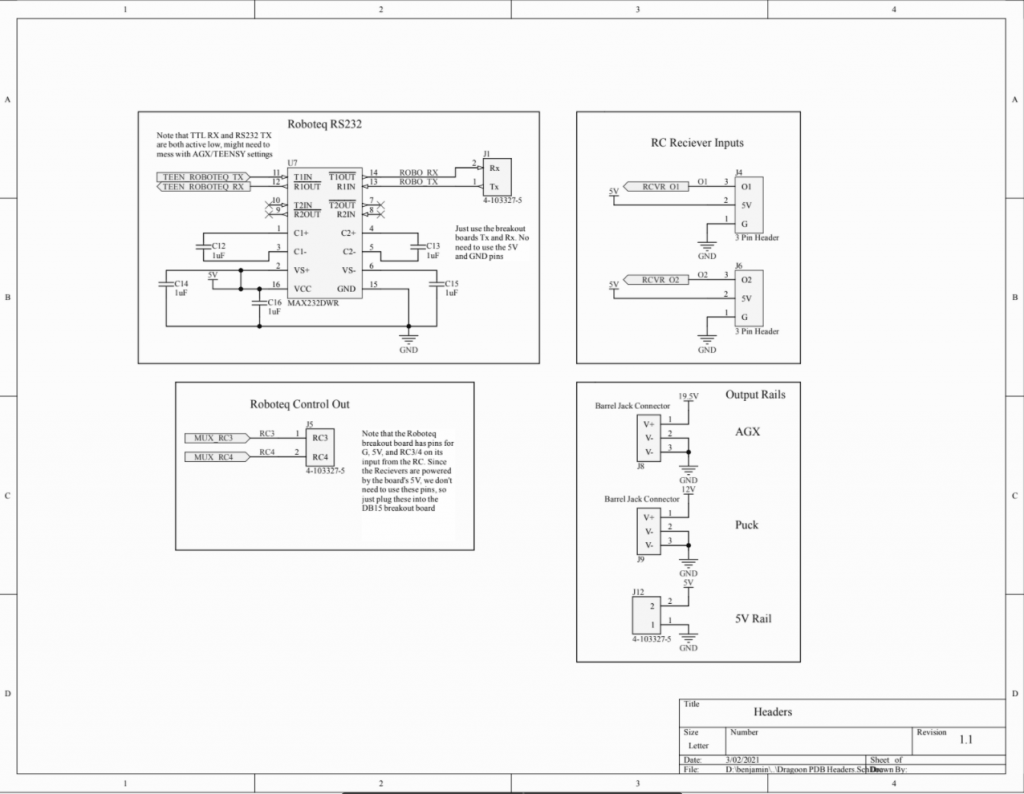
PDB V1 Design Files
Roboteq Controllers User Manual
Roboteq SDC21xx Controller Datasheet
Mechanical
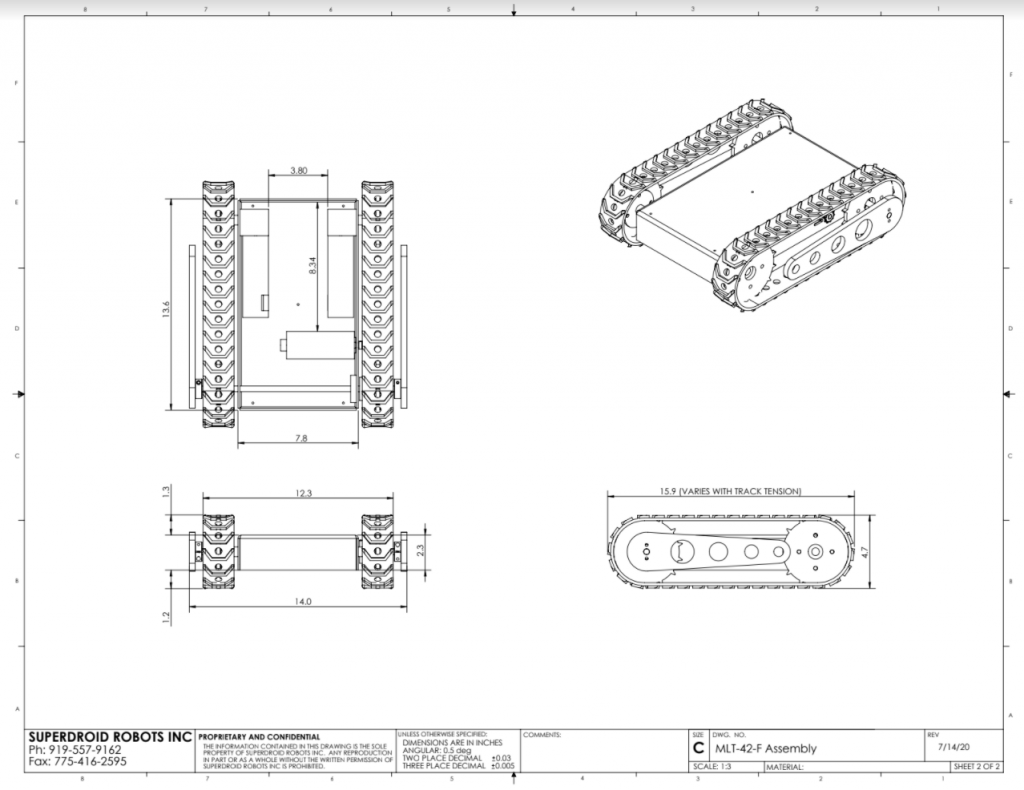
Mechanical Drawing of Robot Base
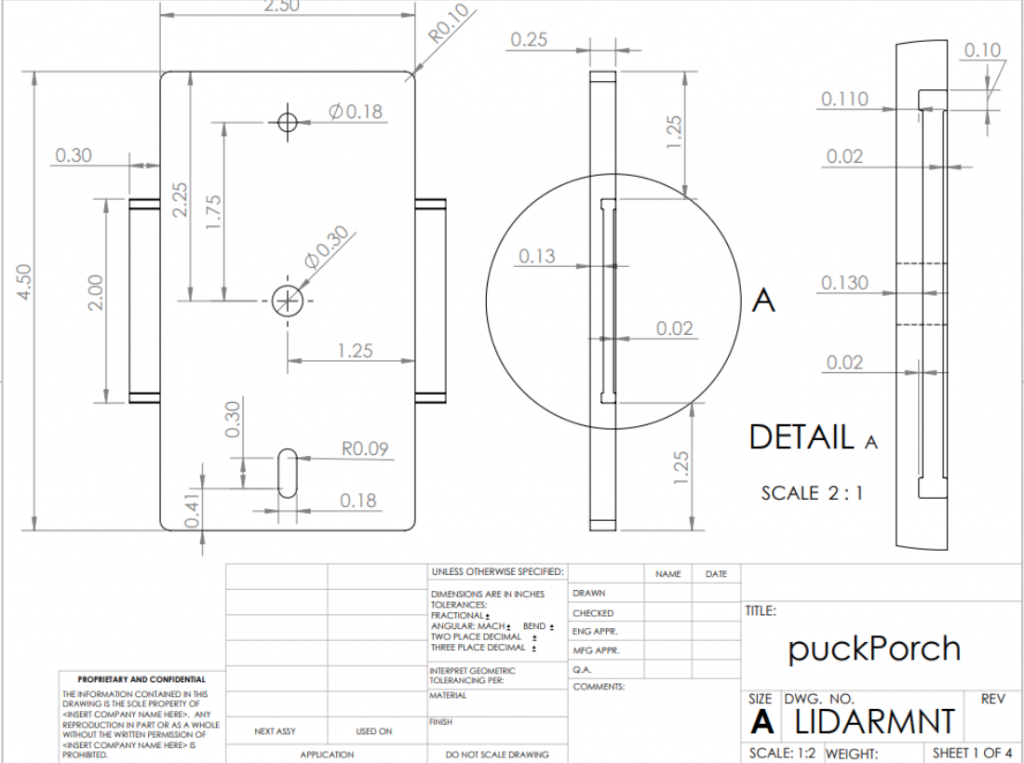
LiDAR mount CAD file
SuperDroid MLT-42 Assembly Manual
Software Flowchart
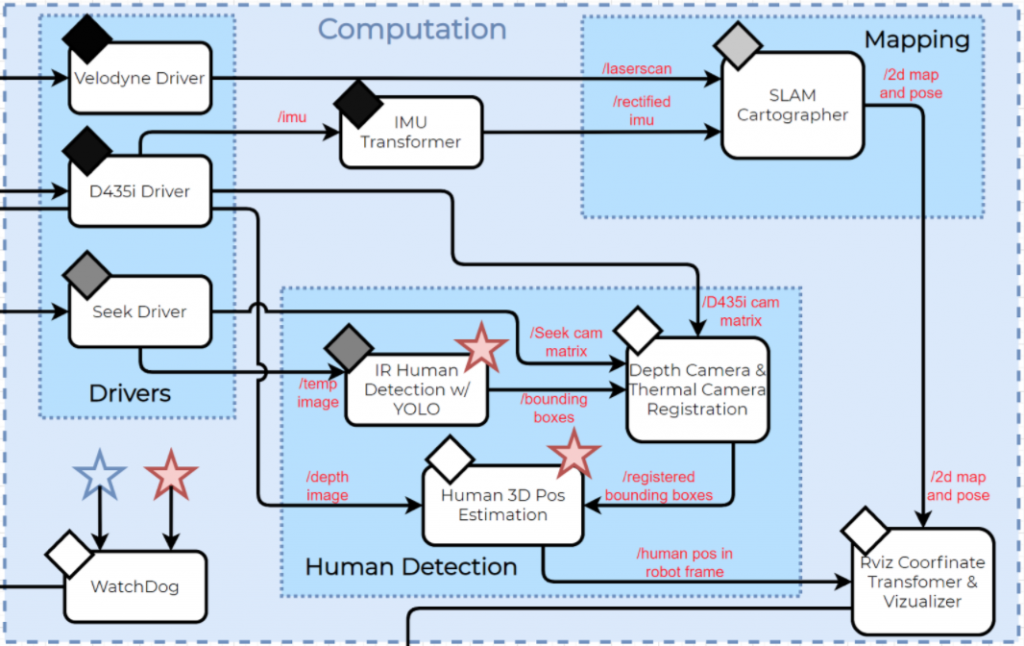
Overview of Software Architecture
Component Testing and Results
Full System Testing
Full system test on 4/12. Visualizer on left and synchronized test footage on right.
Hardware Testing
Robot base mobility test 1 (external video)
Robot base mobility test 2 (external video)
DC Motors working on robot base (external video)
Software Testing
We tested the speed of our human detection and localization algorithm with the following setup:

A foam block is placed in front of Dragoon at the start of the test. We collected the time between the removal of the foam block and the appearance of the human in the correct location on the visualizer.
We performed the test in the following four positions:

Supine Position

Side-lying Position

Seated Position

Standing Position
Below is our aggregate results for our detection times:
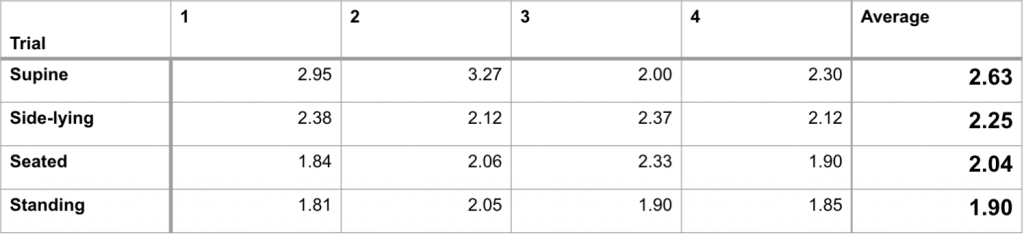
Detection times at a distance of 3m through 4 trials.
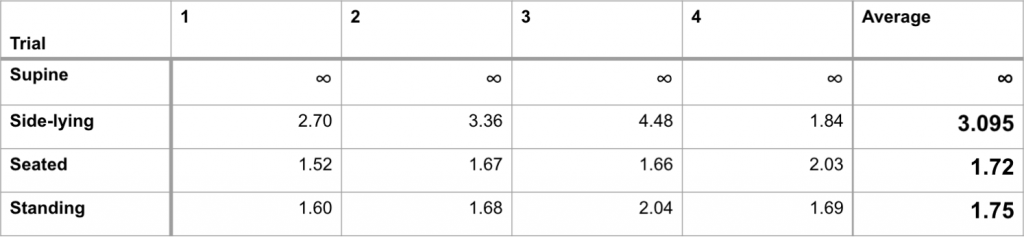
Detection times at a distance of 5m through 4 trials.
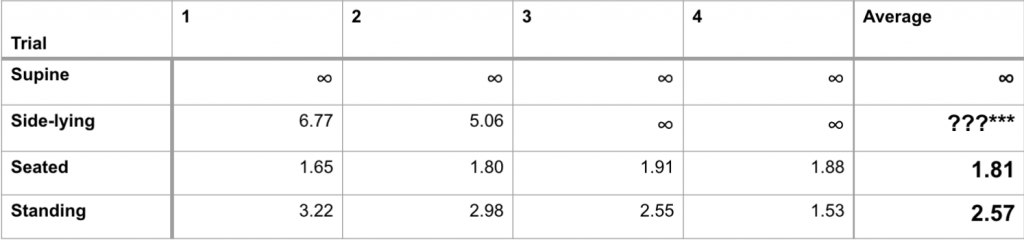
Detection times at a distance of 7m through 4 trials.
Software
# Class: 16-681A, MRSD Project 1
# Team: B, HOWD-E
# Team Members: Dan Bronstein, Kelvin Kang, Ben Kolligs, Jacqueline Liao
# Function: This is a ROS Node that subscribes to the RealSense's depth stream and a RealSense RGB
# YOLO bounding box topic and returns the 3D position of the human relative to the RealSense.
# Date of first revision: 02/08/2021
#!/usr/bin/env python
import rospy
from cv_bridge import CvBridge, CvBridgeError
from sensor_msgs.msg import Image
from sensor_msgs.msg import CameraInfo
from std_msgs.msg import Empty
import pyrealsense2 as rs2
from darknet_ros_msgs.msg import BoundingBoxes
from dragoon_messages.msg import ObjectInfo
from dragoon_messages.msg import Objects
import matplotlib.pyplot as plt
import numpy as np
import cv2
from threading import Lock
# Class for detected YOLO objects
class DetectedObject():
def __init__(self):
self.probability = 0.0
self.id = 0
self.Class = "None"
self.xmin = 0.0
self.xmax = 0.0
self.ymin = 0.0
self.ymax = 0.0
class rgb_human_detection_node():
def __init__(self):
# Define type of depth extraction
self.centroid = False
# self.centroid = True
#hearbeat publisher and heartbeat timer
self.heartbeat_pub = rospy.Publisher('RelLocHeartbeat', Empty, queue_size=1)
self.timer = rospy.Timer(rospy.Duration(1), self.timer_callback)
self.mutex = Lock()
self.binning = True
self.num_bins = 40
self.to_pub = False
self.depth_image = None
# Needed for depth image visualization
self.counter_depth = 0
self.scat_depth = None
# Needed for rgb image visualization
self.counter_rgb = 0
self.scat_rgb = None
# Subscriber for RealSense depth camera intrinsics
self.depthInfoSub = rospy.Subscriber("/camera/depth/camera_info", CameraInfo, self.imageDepthInfoCallback)
# Subscriber for RealSense RGB camera intrinsics
self.rgbInfoSub = rospy.Subscriber("camera/color/camera_info", CameraInfo, self.imageColorInfoCallback)
# Subscriber for YOLO bounding boxes on RGB stream
self.bboxSub = rospy.Subscriber("/darknet_ros/bounding_boxes", BoundingBoxes, self.get_bbox, queue_size=1)
# Subscriber for depth image
self.depthSub = rospy.Subscriber("/camera/depth/image_rect_raw", Image, self.convert_depth_image, queue_size=1) # , buffer_size=10000000
# Subscriber for RGB image - do NOT visualize depth and RGB simultaneously for now
# self.rgbSub = rospy.Subscriber("/camera/color/image_raw", Image, self.show_color_image)
# Publisher that will publish list of poses/object infos as an Objects message
self.pub = rospy.Publisher('ObjectPoses', Objects, queue_size = 1)
# Objects message to be published, consisting of poses/infos stored as ObjectInfo messages
self.poseMsgs = Objects()
# List of objects detected by YOLO in current frame
self.obs = []
self.depth_intrinsics = None
self.color_intrinsics = None
# Hard-coded extrinsics
self.depth_to_color_extrin = rs2.extrinsics()
self.depth_to_color_extrin.translation = [0.0147247, 0.000133323, 0.000350991]
self.depth_to_color_extrin.rotation = [0.999929, 0.01182, -0.00152212, -0.0118143, 0.999923, 0.00370104, 0.00156575, -0.0036828, 0.999992]
self.color_to_depth_extrin = rs2.extrinsics()
self.color_to_depth_extrin.translation = [-0.0147247, 3.93503e-05, -0.000373552]
self.color_to_depth_extrin.rotation = [0.999929, -0.0118143, 0.00156575, 0.01182, 0.999923, -0.0036828, -0.00152212, 0.00370104, 0.999992]
# Depth camera scale (not used in current implementation)
self.depth_scale = 0.0010000000475
# Minimum detectable depth
self.depth_min = 0.11
# Maximum detectable depth
self.depth_max = 10.0
# Projects a pixel from RGB frame to depth frame. Reference C++ code in link below:
# http://docs.ros.org/en/kinetic/api/librealsense2/html/rsutil_8h_source.html#l00186
# Difference is that I pass in converted depth from CvBridge instead of calculating depth using depth scale and raw depth data in line 213
def project_color_to_depth(self, depth_image, from_pixel):
to_pixel = [0.0,0.0]
min_point = rs2.rs2_deproject_pixel_to_point(self.color_intrinsics, from_pixel, self.depth_min)
min_transformed_point = rs2.rs2_transform_point_to_point(self.depth_to_color_extrin, min_point)
# min_transformed_point = rs2.rs2_transform_point_to_point(self.color_to_depth_extrin, min_point)
start_pixel = rs2.rs2_project_point_to_pixel(self.depth_intrinsics, min_transformed_point)
start_pixel = rs2.adjust_2D_point_to_boundary(start_pixel,self.depth_intrinsics.width, self.depth_intrinsics.height)
max_point = rs2.rs2_deproject_pixel_to_point(self.color_intrinsics, from_pixel, self.depth_max)
max_transformed_point = rs2.rs2_transform_point_to_point(self.depth_to_color_extrin, max_point)
# max_transformed_point = rs2.rs2_transform_point_to_point(self.color_to_depth_extrin, max_point)
end_pixel = rs2.rs2_project_point_to_pixel(self.depth_intrinsics, max_transformed_point)
end_pixel = rs2.adjust_2D_point_to_boundary(end_pixel,self.depth_intrinsics.width, self.depth_intrinsics.height)
min_dist = -1.0
p = [start_pixel[0], start_pixel[1]]
next_pixel_in_line = rs2.next_pixel_in_line([start_pixel[0],start_pixel[1]], start_pixel, end_pixel)
while rs2.is_pixel_in_line(p, start_pixel, end_pixel):
depth = depth_image[int(p[1])*self.depth_intrinsics.width+int(p[0])]/1000.0
if depth == 0:
p = rs2.next_pixel_in_line(p, start_pixel, end_pixel)
continue
point = rs2.rs2_deproject_pixel_to_point(self.depth_intrinsics, p, depth)
transformed_point = rs2.rs2_transform_point_to_point(self.color_to_depth_extrin, point)
# transformed_point = rs2.rs2_transform_point_to_point(self.depth_to_color_extrin, point)
projected_pixel = rs2.rs2_project_point_to_pixel(self.color_intrinsics, transformed_point)
new_dist = (projected_pixel[1]-from_pixel[1])**2+(projected_pixel[0]-from_pixel[0])**2
if new_dist < min_dist or min_dist < 0:
min_dist = new_dist
to_pixel[0] = p[0]
to_pixel[1] = p[1]
p = rs2.next_pixel_in_line(p, start_pixel, end_pixel)
return to_pixel
# Call this function to get depth intrinsics
def imageDepthInfoCallback(self, cameraInfo):
if self.depth_intrinsics:
return
self.depth_intrinsics = rs2.intrinsics()
self.depth_intrinsics.width = cameraInfo.width
self.depth_intrinsics.height = cameraInfo.height
self.depth_intrinsics.ppx = cameraInfo.K[2]
self.depth_intrinsics.ppy = cameraInfo.K[5]
self.depth_intrinsics.fx = cameraInfo.K[0]
self.depth_intrinsics.fy = cameraInfo.K[4]
if cameraInfo.distortion_model == "plumb_bob":
self.depth_intrinsics.model = rs2.distortion.brown_conrady
elif cameraInfo.distortion_model == "equidistant":
self.depth_intrinsics.model = rs2.distortion.kannala_brandt4
self.depth_intrinsics.coeffs = [i for i in cameraInfo.D]
# Call this function to get RGB intrinsics
def imageColorInfoCallback(self, cameraInfo):
if self.color_intrinsics:
return
self.color_intrinsics = rs2.intrinsics()
self.color_intrinsics.width = cameraInfo.width
self.color_intrinsics.height = cameraInfo.height
self.color_intrinsics.ppx = cameraInfo.K[2]
self.color_intrinsics.ppy = cameraInfo.K[5]
self.color_intrinsics.fx = cameraInfo.K[0]
self.color_intrinsics.fy = cameraInfo.K[4]
if cameraInfo.distortion_model == "plumb_bob":
self.color_intrinsics.model = rs2.distortion.brown_conrady
elif cameraInfo.distortion_model == "equidistant":
self.color_intrinsics.model = rs2.distortion.kannala_brandt4
self.color_intrinsics.coeffs = [i for i in cameraInfo.D]
# CGet 3D position from YOLO bounding box, publish position
def get_bbox(self, bounding_box_msg):
temp_obs = []
for bbox in bounding_box_msg.bounding_boxes:
if bbox.Class == 'person':
temp_obs.append(bbox)
temp_image = None
if self.depth_image is None:
return
elif self.depth_intrinsics is None:
return
elif self.color_intrinsics is None:
return
else:
temp_image = self.depth_image.copy()
#clear previous msgs
self.poseMsgs = Objects()
for obj in temp_obs:
# Get YOLO bbox corners
color_points = [
[float(obj.xmin), float(obj.ymin)],
[float(obj.xmax), float(obj.ymin)],
[float(obj.xmin), float(obj.ymax)],
[float(obj.xmax), float(obj.ymax)]
]
# Convert each corner from color image to depth image
depth_points = []
for color_point in color_points:
depth_flattened = temp_image.flatten()
depth_point = self.project_color_to_depth(depth_flattened, color_point)
depth_points.append(depth_point)
depth_points = np.array(depth_points)
color_points = np.array(color_points)
# Visualize bboxes in depth image
# if self.scat_depth != None:
# self.scat_depth.remove()
# plt.imshow(depth_image)
# self.scat_depth = plt.scatter(depth_points[:,0],depth_points[:,1])
# plt.show()
# plt.pause(0.00000000001)
# im_plotted = temp_image.copy()
# for p in depth_points:
# for p in color_points:
# im_plotted = cv2.circle(im_plotted, (int(p[0]), int(p[1])), 10, (0,0,255), -1)
# Get mins and maxes of depth image bbox
depth_xmin = min(depth_points[:,0])
depth_xmax = max(depth_points[:,0])
depth_ymin = min(depth_points[:,1])
depth_ymax = max(depth_points[:,1])
# Convert the depth image to a Numpy array
depth_array = np.array(temp_image, dtype=np.float32)
# Find all pixel depth in bbox in order to find mode (best_depth)
if self.binning:
bbox_pixel_depths = []
for i in range(int(depth_xmin), int(depth_xmax)):
for j in range(int(depth_ymin), int(depth_ymax)):
bbox_pixel_depths.append(depth_array[j, i])
hist, bin_edges = np.histogram(bbox_pixel_depths, bins=self.num_bins)
max_index = np.argmax(hist)
best_depth = (bin_edges[max_index]+bin_edges[max_index+1])/2000.0
# Get position of center of bbox
bbox_center_x = int((depth_xmax+depth_xmin)/2)
bbox_center_y = int((depth_ymax+depth_ymin)/2)
if self.depth_intrinsics:
# Extract depth of center pixel
center_depth = depth_array[bbox_center_y, bbox_center_x]
# Get 3D pose of point in depth frame
result = rs2.rs2_deproject_pixel_to_point(self.depth_intrinsics, [bbox_center_x, bbox_center_y], center_depth)
# New poseMsg with 3D pose info, probability, id, and class from YOLO
poseMsg = ObjectInfo()
poseMsg.pose.x = result[0]/1000.0
poseMsg.pose.y = result[1]/1000.0
if self.binning:
poseMsg.pose.z = best_depth
elif self.centroid:
poseMsg.pose.z = result[2]/1000.0
poseMsg.probability = obj.probability
poseMsg.id = obj.id
poseMsg.Class = obj.Class
# Add new poseMsg to poseMsgs, Objects msg that will be published
self.poseMsgs.objects_info.append(poseMsg)
# Publish Objects msg for frame once all YOLO objects are processed
if len(temp_obs) != 0:
self.pub.publish(self.poseMsgs)
# Convert raw depth data to actual depth, get actual depth info of YOLO bboxes and publish to 'ObjectPoses'
def convert_depth_image(self, ros_image):
# Use cv_bridge() to convert the ROS image to OpenCV format
bridge = CvBridge()
# Convert the depth image using the default passthrough encoding
self.depth_image = bridge.imgmsg_to_cv2(ros_image, desired_encoding="passthrough")
# Visulize RGB stream with all bboxes
def show_color_image(self, ros_image):
if self.counter_rgb % 10 == 0:
bridge_color = CvBridge()
color_image = bridge_color.imgmsg_to_cv2(ros_image, desired_encoding="passthrough")
for obj in self.obs:
if self.scat_rgb != None:
self.scat_rgb.remove()
#plt.imshow(color_image)
#self.scat_rgb = plt.scatter(np.array([obj.xmin, obj.xmin, obj.xmax, obj.xmax]),np.array([obj.ymin, obj.ymax, obj.ymin, obj.ymax]))
#plt.show()
#plt.pause(0.00000000001)
self.counter_rgb += 1
def timer_callback(self, timer):
msg = Empty()
self.heartbeat_pub.publish(msg)
def main():
rospy.init_node('rgbHD',anonymous=True)
rgbDetectionNode = rgb_human_detection_node()
# These two lines needed for continuous visualization
#plt.ion()
#plt.show()
rospy.spin()
if __name__ == '__main__':
main()
Presentations
Conceptual Design Report (external link)
Preliminary Design Review (external link)
Critical Design Review (external link)
Critical Design Review Report (external link)
System Development Review (external link)
Standards and Regulations (external link)
Final Report (external link)
ILRs
Daniel Bronstein
ILR1 (external link)
ILR2 (external link)
ILR3 (external link)
ILR4 (external link)
ILR5 (external link)
ILR6 (external link)
ILR7 (external link)
ILR8 (external link)
ILR9 (external link)
ILR10 (external link)
Kelvin Kang
ILR1 (external link)
ILR2 (external link)
ILR3 (external link)
ILR4 (external link)
ILR5 (external link)
ILR6 (external link)
ILR7 (external link)
ILR8 (external link)
ILR9 (external link)
ILR10 (external link)
Ben Kolligs
ILR1 (external link)
ILR2 (external link)
ILR3 (external link)
ILR4 (external link)
ILR5 (external link)
ILR6 (external link)
ILR7 (external link)
ILR8 (external link)
ILR9 (external link)
ILR10 (external link)
Jacqueline Liao
ILR1 (external link)
ILR2 (external link)
ILR3 (external link)
ILR4 (external link)
ILR5 (external link)
ILR6 (external link)
ILR7 (external link)
ILR8 (external link)
ILR9 (external link)
ILR10 (external link)