The architecture for the Vehicle and Environment Detection subsystem looks like the following,
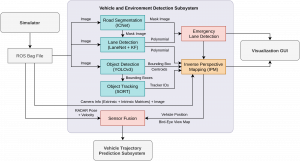
![]()
The first step is to detect all the vehicles in the scene. The object detection is performed using YOLOv3 and is integrated in the pipeline. Object tracking is implemented with the help SORT, which is an approach to multiple object tracking where the main focus is to associate objects efficiently for online and real-time applications. Now that we have some information about the positions of vehicles in the 2D image, we need to further localize them in the real-world as well as track them over the frames. For this task, we need to first figure out where the road region and the location of lanes are. For lane marking detection LaneNet, a deep learning based approach along with an additional moving average filter for smoothing. The pipeline currently uses IC Net for semantic segmentation. The object detection, lane marking detection, and semantic segmentation models run in parallel to perceive the environment. To make sense of all the detections in perception, we first have to make sense of the road lane markings and road area. With the later data only we can figure out if the detected vehicles/ obstacles are in our lane or oncoming lane. Recovering the 3D velocity of the vehicles solely based on vision is very challenging and inaccurate,especially for long range detection. RADAR is excellent for determining speed of oncoming vehicles and operation in adverse weather and lighting conditions, whereas camera provides rich visual features required for object classification. The position and velocity estimates are improved through the sensor fusion of RADAR and camera. Although sensor fusion is currently not complete, some of the sub tasks such as Inverse Perspective Mapping and RADAR integration have been completed this semester. The idea behind this is to create a birds-eye-view of the environment around the vehicle by using a perspective transformation. Using this birds-eye-view representation and some known priors such as camera parameters and extrinsics with respect to a calibration checkerboard, all the vehicles can be mapped to their positions in the real-world. Fusion of this data along with RADAR targets can provide us reliable states of all vehicles in the scene. Finally, an occupancy grid will be generated which can be used for prediction and planning
For more information about this subsystem, see our subsystems description.